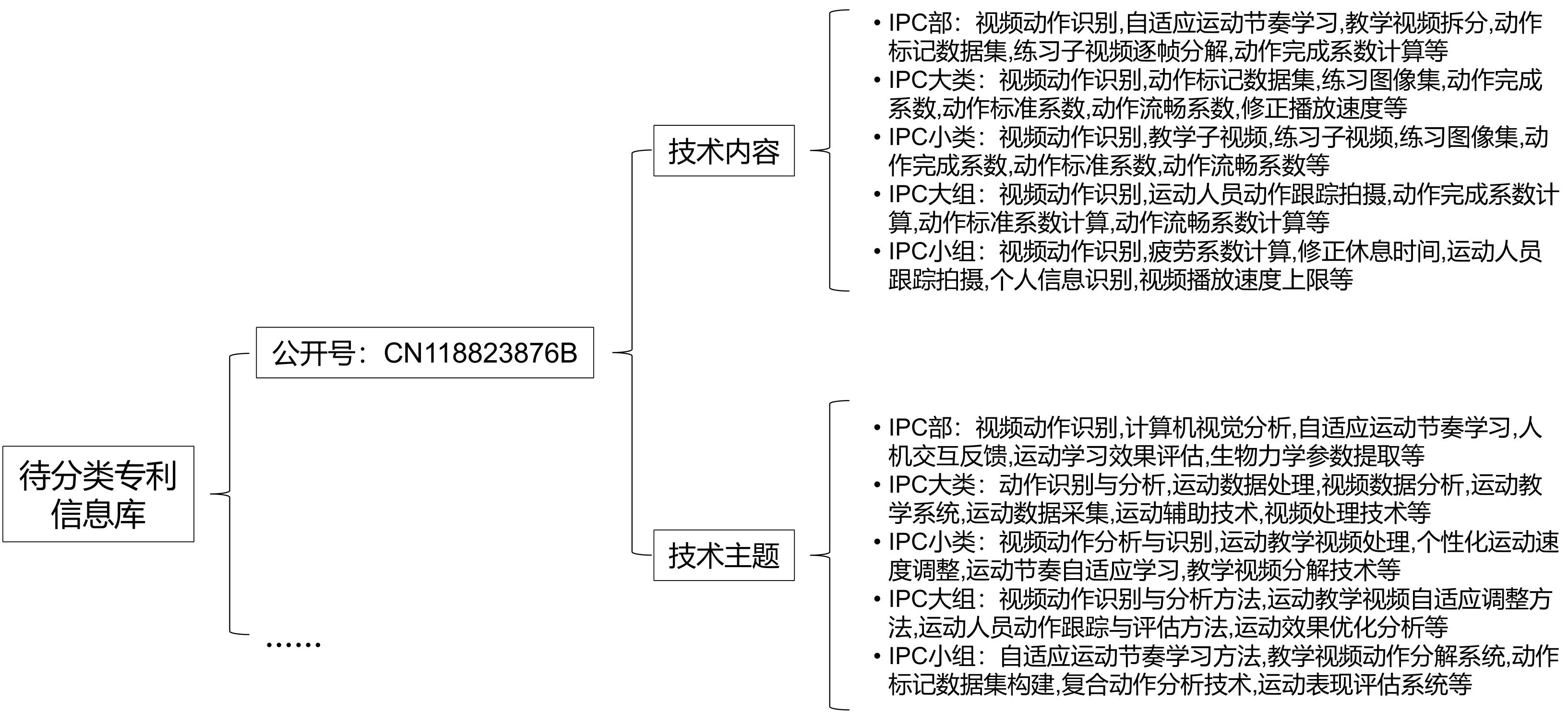
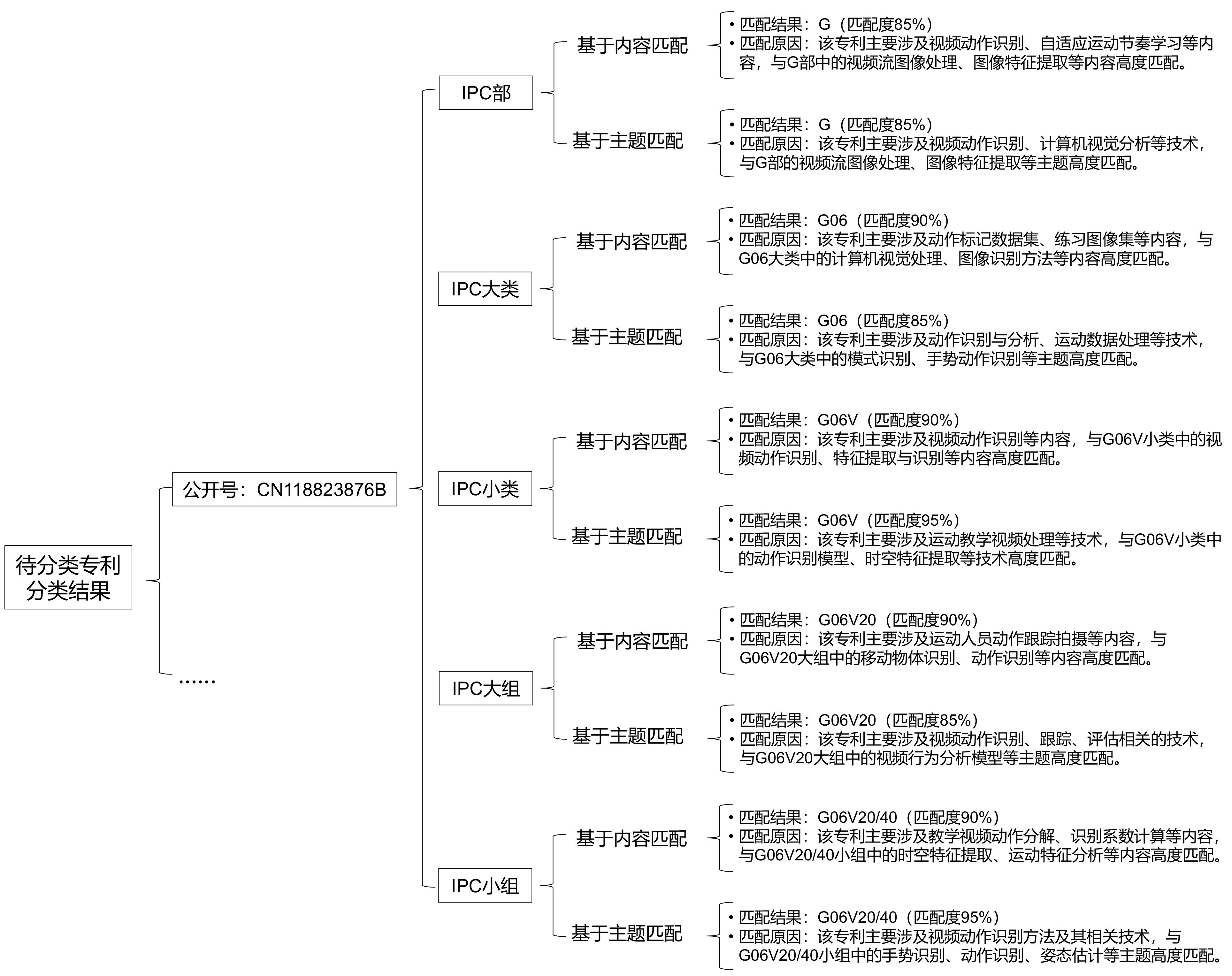
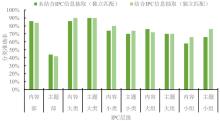
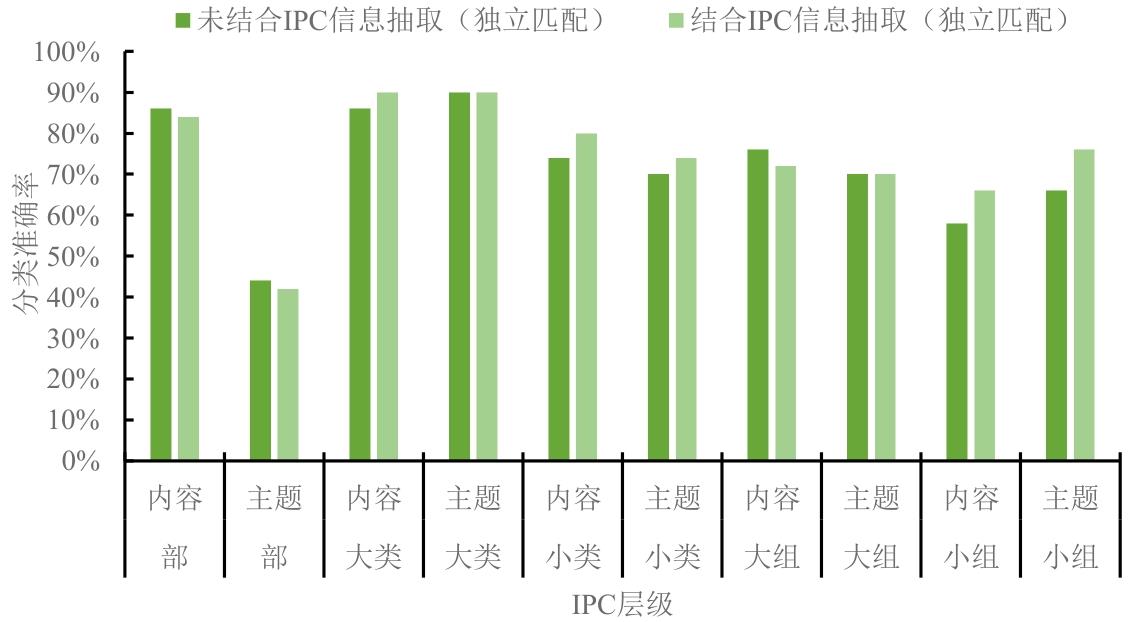
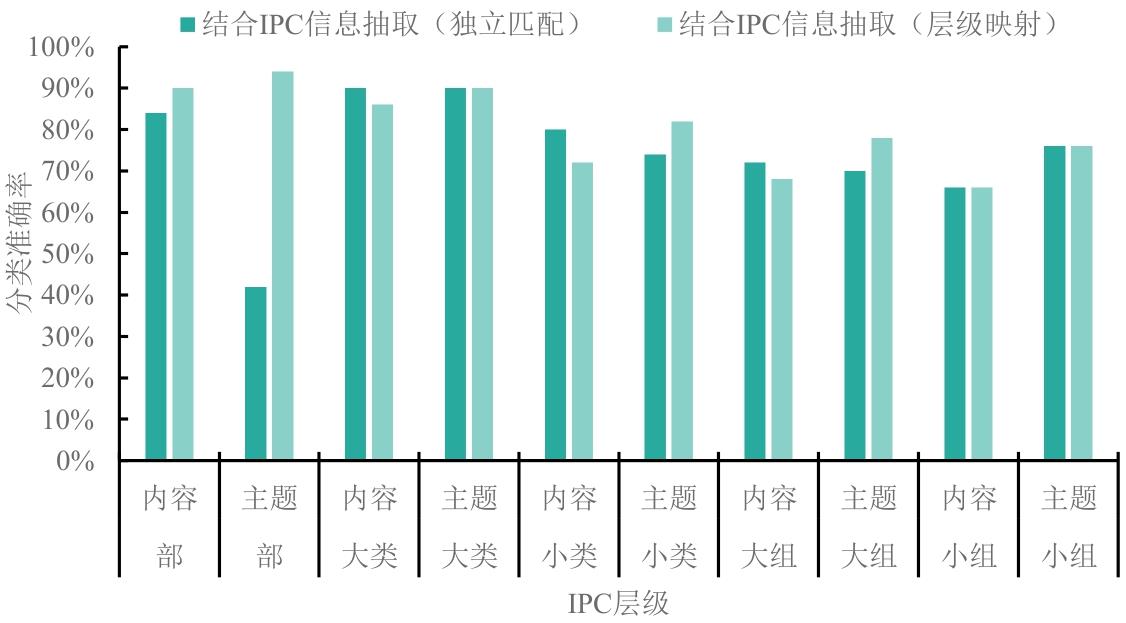
| [1] |
韩洪灵, 董恬媛, 刘强, 等. 专利加速审查与企业创新[J/OL]. 南开管理评论, 1-31[2025-06-11].
|
|
Han Hongling, Dong Tianyuan, Liu Qiang, et al. Patent accelerated examination and corporate innovation[J/OL]. Nankai Business Review, 1-31[2025-06-11].
|
| [2] |
中国政府网. 这一领域多个全球第一!看最新安排[EB/OL]. (2025-04-24)[2025-06-11].
|
| [3] |
项芮, 孙巍. 基于PhraseLDA-SNA和机器学习的技术主题影响力测度方法研究[J]. 农业图书情报学报, 2024, 36(4): 45-62.
|
|
Xiang Rui, Sun Wei. Methodology for assessing the influence of technical topics based on PhraseLDA-SNA and machine learning[J]. Journal of Library and Information Science in Agriculture, 2024, 36(4): 45-62.
|
| [4] |
吴玉莲. 大模型技术在专利领域中的应用研究系统综述[J]. 中国发明与专利, 2025, 22(4): 66-76.
|
|
Wu Yulian. A systematic review of the application of large language models in patents[J]. China Invention & Patent, 2025, 22(4): 66-76.
|
| [5] |
朱梦珂, 朱一帆, 上官博屹, 等. 基于大语言模型的思维链技术应用展望[C]//第十三届中国指挥控制大会论文集. 2025: 258-263.
|
| [6] |
吴洁, 桂亮, 刘鹏, 等. 多维特征视角下基于图卷积网络的专利技术领域自动识别研究[J]. 中国管理科学, 2022, 30(12): 185-197.
|
|
Wu Jie, Gui Liang, Liu Peng, et al. Patent classification based on multi-dimensional feature and graph convolutional networks[J]. Chinese Journal of Management Science, 2022, 30(12): 185-197.
|
| [7] |
Chang S B, Lai K K, Chang Shumin. Exploring technology diffusion and classification of business methods: Using the patent citation network[J]. Technological Forecasting and Social Change, 2009, 76(1): 107-117.
|
| [8] |
Lai K K, Wu S J. Using the patent co-citation approach to establish a new patent classification system[J]. Information Processing & Management, 2005, 41(2): 313-330.
|
| [9] |
Fang Lintao, Zhang Le, Wu Han, et al. Patent2Vec: Multi-view representation learning on patent-graphs for patent classification[J]. World Wide Web, 2021, 24(5): 1791-1812.
|
| [10] |
Fall C J, Törcsvári A, Benzineb K, et al. Automated categorization in the international patent classification[J]. ACM SIGIR Forum, 2003, 37(1): 10-25.
|
| [11] |
杨超宇, 陈雯君, 耿显亚. 基于改进SVM的中文专利文本分类比较研究[J]. 武汉理工大学学报(信息与管理工程版), 2023, 45(2): 292-298, 303.
|
|
Yang Chaoyu, Chen Wenjun, Geng Xianya. Comparative study on Chinese patent text classification based on improved SVM[J]. Journal of Wuhan University of Technology (Information & Management Engineering), 2023, 45(2): 292-298, 303.
|
| [12] |
贾杉杉, 刘畅, 孙连英, 等. 基于多特征多分类器集成的专利自动分类研究[J]. 数据分析与知识发现, 2017, 1(8): 76-84.
|
|
Jia Shanshan, Liu Chang, Sun Lianying, et al. Patent classification based on multi-feature and multi-classifier integration[J]. Data Analysis and Knowledge Discovery, 2017, 1(8): 76-84.
|
| [13] |
慎金花, 陈红艺, 张更平, 等. 基于层次分类器的专利文本分类模型研究[J]. 情报杂志, 2023, 42(8): 157-163, 68.
|
|
Shen Jinhua, Chen Hongyi, Zhang Gengping, et al. Research on patent text classification model based on hierarchical classifier[J]. Journal of Intelligence, 2023, 42(8): 157-163, 68.
|
| [14] |
Verberne S, Vogel M, D'Hondt E. Patent classification experiments with the Linguistic classification system LCS[C]//CLEF 2010 LABs and Workshops, Notebook Papers. Padua: CLEF, 2010.
|
| [15] |
Stutzki J, Schubert M. Geodata supported classification of patent applications[J]. ACM Transactions on Spatial Algorithms and Systems, 2016, 2(3): 1-18.
|
| [16] |
马双刚. 基于深度学习理论与方法的中文专利文本自动分类研究[D]. 镇江: 江苏大学, 2016.
|
|
Ma Shuanggang. The Study of Automatic Chinese Patent Classification Based on Deep Learning Theory and Method[D]. Zhenjiang: Jiangsu University, 2016.
|
| [17] |
胡杰, 李少波, 于丽娅, 等. 基于卷积神经网络与随机森林算法的专利文本分类模型[J]. 科学技术与工程, 2018, 18(6): 268-272.
|
|
Hu Jie, Li Shaobo, Yu Liya, et al. A patent classification model based on convolutional neural networks and rand forest[J]. Science Technology and Engineering, 2018, 18(6): 268-272.
|
| [18] |
马建红, 王瑞杨, 姚爽, 等. 基于深度学习的专利分类方法[J]. 计算机工程, 2018, 44(10): 209-214.
|
|
Ma Jianhong, Wang Ruiyang, Yao Shuang, et al. Patent classification method based on depth learning[J]. Computer Engineering, 2018, 44(10): 209-214.
|
| [19] |
金晶, 陶皖, 皇苏斌, 等. 基于混合嵌入的专利数据层次多标签分类模型研究[J]. 长春理工大学学报(自然科学版), 2025, 48(2): 91-101.
|
|
Jin Jing, Tao Wan, Huang Subin, et al. Research on hierarchical multi-label classification model of patent data based on hybrid embedding[J]. Journal of Changchun University of Science and Technology, 2025, 48(2): 91-101.
|
| [20] |
Li Shaobo, Hu Jie, Cui Yuxin, et al. DeepPatent: Patent classification with convolutional neural networks and word embedding[J]. Scientometrics, 2018, 117(2): 721-744.
|
| [21] |
Haghighian Roudsari A, Afshar J, Lee W, et al. PatentNet: Multi-label classification of patent documents using deep learning based on language understanding[J]. Scientometrics, 2022, 127(1): 207-231.
|
| [22] |
Jung G, Shin J, Lee S. Impact of preprocessing and word embedding on extreme multi-label patent classification tasks[J]. Applied Intelligence, 2023, 53(4): 4047-4062.
|
| [23] |
Xu Xuejie, Xu Yi, Miao Ziqi, et al. Memory-enhanced hierarchical and temporal semantic learning for multi-label patent classification[J]. Expert Systems with Applications, 2025, 285: 127556.
|
| [24] |
Qiang Yifan, Sun Gaojie, Liu Hui. PatentALL: Multi-label patent classification using adaptive label learning[C]//2024 IEEE 36th International Conference on Tools with Artificial Intelligence (ICTAI). Piscataway, New Jersey: IEEE, 2024: 108-115.
|
| [25] |
Bekamiri H, Hain D S, Jurowetzki R. PatentSBERTa: A deep NLP based hybrid model for patent distance and classification using augmented SBERT[J]. Technological Forecasting and Social Change, 2024, 206: 123536.
|
| [26] |
Li Munan, Wang Liang. Leveraging patent classification based on deep learning: The case study on smart cities and industrial Internet of Things[J]. Journal of Informetrics, 2025, 19(1): 101616.
|
| [27] |
Kamateri E, Salampasis M, Perez-Molina E. Will AI solve the patent classification problem?[J]. World Patent Information, 2024, 78: 102294.
|
| [28] |
Yoshikawa N, Krestel R. Do large language models understand patents? Enhancing patent classification through AI-generated summaries[J]. World Patent Information, 2025, 81: 102353.
|
| [29] |
Rafieian B, Vázquez P P. Improved multi-label hierarchical patent classification using LLMs[J]. World Patent Information, 2025, 81: 102356.
|
| [30] |
国家知识产权局. 国际专利分类使用指南(2025版)[EB/OL]. (2025-05-08)[2025-06-11].
|
| [31] |
吕国燕, 戴佳呈, 吕学强, 等. 中文专利文本结构信息提取方法[J]. 计算机工程与设计, 2025, 46(3): 665-672.
|
|
Lv Guoyan, Dai Jiacheng, Lv Xueqiang, et al. Extraction method of Chinese patent text structure information[J]. Computer Engineering and Design, 2025, 46(3): 665-672.
|


 ), 吕璐成1,2, 苏莹1,2
), 吕璐成1,2, 苏莹1,2