

农业图书情报学报 ›› 2025, Vol. 37 ›› Issue (2): 4-22.doi: 10.13998/j.cnki.issn1002-1248.25-0116
• 特约综述 • 下一篇
蔡祎然1,2, 胡正银1,2( ), 刘春江1,2
), 刘春江1,2
收稿日期:2025-01-06
出版日期:2025-02-05
发布日期:2025-05-20
通讯作者:
胡正银
作者简介:蔡祎然(2001- ),女,硕士研究生,研究方向为科技文献数据挖掘、学科知识发现
刘春江(1984- ),男,博士,高级工程师,研究方向为科技文献数据挖掘
基金资助:
CAI Yiran1,2, HU Zhengyin1,2(), LIU Chunjiang1,2
Received:2025-01-06
Online:2025-02-05
Published:2025-05-20
Contact:
HU Zhengyin
摘要:
[目的/意义] 科技文献蕴含丰富的领域知识与科学数据,可为人工智能驱动的科学研究(AI for Science,AI4S)提供高质量数据支撑。本文系统梳理大语言模型(Large Language Models,LLMs)在科技文献数据挖掘中的方法技术、软件工具及应用场景,探讨其研究方向与发展趋势。 [方法/过程] 本文基于文献调研与归纳总结,在方法技术层面,从文本知识、科学数据与图表信息分析了LLMs驱动的科技文献细粒度数据挖掘关键技术以及综合性知识生成的方法;在软件工具层面,归纳了主流LLMs科技文献数据挖掘与知识生成工具的方法技术、核心功能和适用场景;在应用场景层面,分析了科技文献数据挖掘应用于LLMs的实践价值。 [结果/结论] 在方法技术方面,通过动态提示学习框架与领域适配微调等技术,LLMs极大提升科技文献数据挖掘精度与效度;在软件工具方面,已初步形成从数据标注、数据挖掘、合成数据到知识生成的全流程LLMs科技文献数据挖掘工具链;在应用方面,科技文献数据可为LLMs提供专业化语料和高质量数据,LLMs推动科技文献从单维数据服务向多模态知识生成服务的范式演进。然而,当前仍面临领域知识表征深度不足、跨模态推理效率较低、知识生成可解释性欠缺等挑战。未来应着重研发具有可解释性与跨领域适应性的LLMs科技文献数据挖掘工具,集成“人在回路”的协同机制,促进科技文献数据挖掘从效率优化向知识创造转变。
中图分类号: G350,G203
蔡祎然, 胡正银, 刘春江. 大语言模型赋能科技文献数据挖掘进展分析[J]. 农业图书情报学报, 2025, 37(2): 4-22.
CAI Yiran, HU Zhengyin, LIU Chunjiang. Analysis of Progress in Data Mining of Scientific Literature Using Large Language Models[J]. Journal of library and information science in agriculture, 2025, 37(2): 4-22.
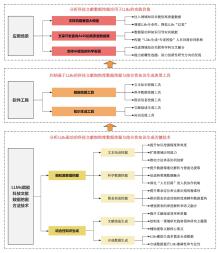
图1
大语言模型赋能科技文献数据挖掘进展分析整体框架图"
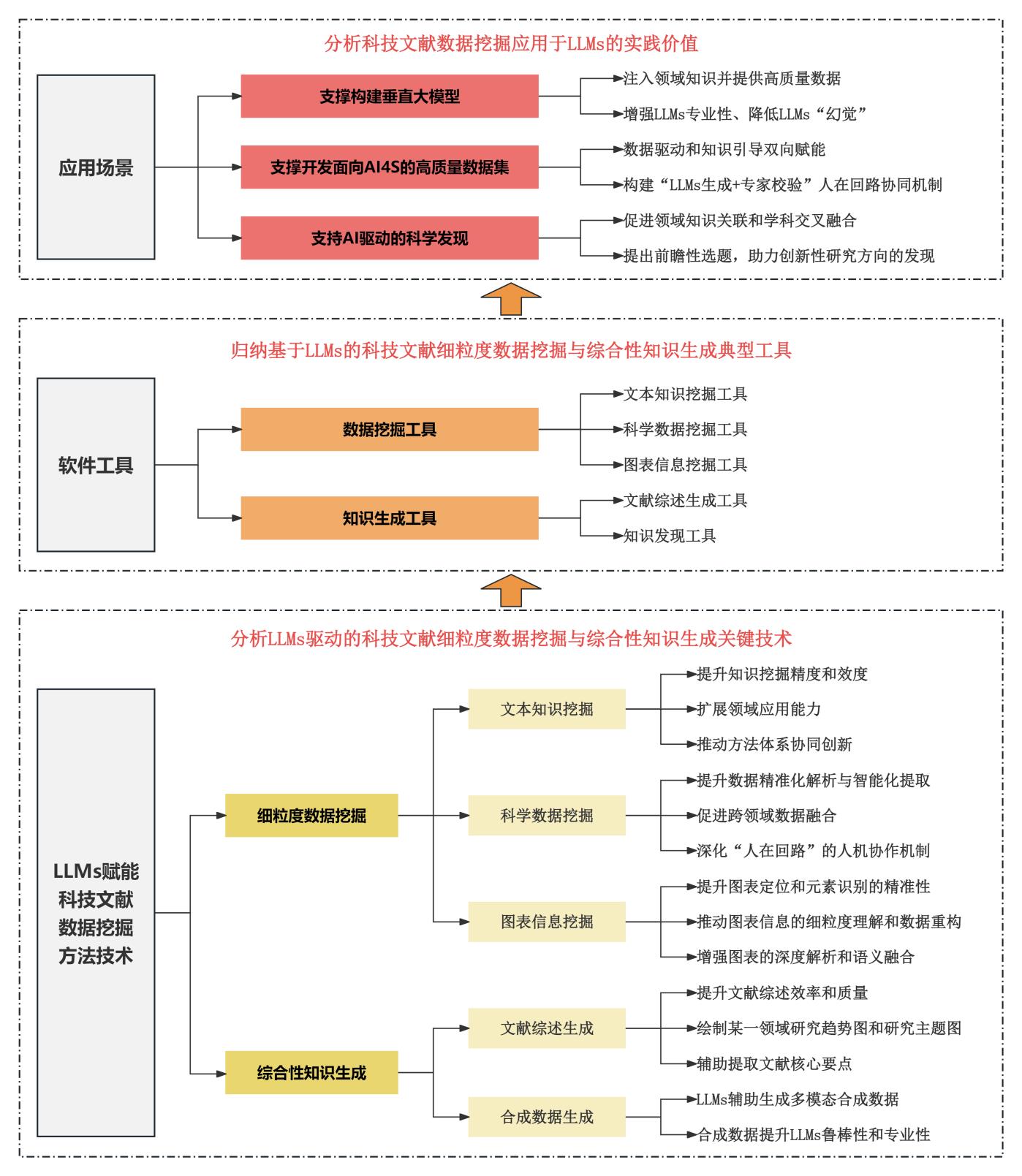
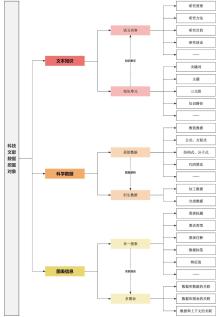
图2
科技文献数据挖掘的对象"

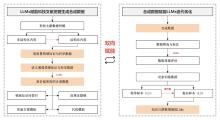
图3
科技文献合成数据与LLMs双向赋能框架"

表1
基于大语言模型的科技文献数据挖掘和知识生成方法技术"
| 类别 | 功能 | 方法技术 |
|---|---|---|
| 数据挖掘 | 文本知识挖掘 | 上下文学习[ 工具调用与API集成[ |
| 科学数据挖掘 | 思维链提示[ | |
| 图表信息挖掘 | 上下文学习[ | |
| 知识生成 | 文献综述生成 | 少样本提示[ |
| 合成数据生成 | 上下文学习[ |
表2
大语言模型赋能科技文献数据挖掘的典型工具"
| 类型 | 功能 | 工具名称 | 方法技术 | 应用场景 |
|---|---|---|---|---|
| 数据挖掘 | 文本知识挖掘 | LitAI[ | OCR、上下文学习、 少样本提示、思维链提示 | 文本抽取和结构化、文本质量增强 文本分类、纠正语法错误、参考文献管理 |
| GOT-OCR2.0[ | 注意力机制、上下文学习 多阶段预训练、指令微调 | 文本识别、文档数字化 | ||
| SciAIEngine[ | 自然语言处理、少样本提示、提示工程 | 语步识别、命名实体识别 科技文献挖掘、深度聚类等 | ||
| MDocAgent[ | OCR、RAG 上下文学习、GraphRAG | 多模态数据融合、文本识别和抽取、文档问答 | ||
| LongDocURL[ | 特征融合、RAG、OCR | 长文档解析、文档问答 | ||
| 科学数据挖掘 | LitAI[ | OCR、上下文学习 少样本提示、思维链提示 | 科学数据抽取 | |
| MinerU | 上下文学习、多模态融合 基于人类反馈的强化学习 | 多模态科学数据挖掘 数字公式识别、方程式分子结构式挖掘 | ||
| TableGPT2[ | 注意力机制、神经网络架构 | 表格数据理解、数据管理、数据计算分析 | ||
| GOT-OCR2.0[ | 注意力机制、上下文学习 多阶段预训练、指令微调 | 数字公式识别、方程式分子结构式挖掘 | ||
| olmOCR[ | OCR、文档锚定、微调、思维链提示 | 数字公式识别、方程式分子结构式挖掘 | ||
| 图表信息挖掘 | LitAI[ | OCR、上下文学习 少样本提示、思维链提示 | 图注抽取与解释、图像数据与文本数据关联 图表语义增强 | |
| olmOCR[ | OCR、微调、思维链提示 | 表格识别、提取图表中的关键数据点 | ||
| 知识生成 | 文献综述生成 | Agent Laboratory[ | 思维链提示、基于Transformer架构 | 文献综述、实验设计与分析 代码生成、结果解释、报告撰写 |
| Web of Science研究助手 | 上下文学习、思维链提示 | 文献综述、期刊推荐、数据可视化 | ||
| SciAIEngine[ | 自然语言处理、少样本提示、提示工程 | 文本标题生成、结构化自动综述 | ||
| Deep Research | 自然语言处理、端到端强化学习 | 文献综述、论文润色、生成报告 | ||
| AutoSurvey[ | RAG、提示工程、词嵌入 | 初始检索与大纲生成、子章节起草 整合与优化、评估与迭代 | ||
| 知识发现 | VirSci[ | RAG、多任务学习 模型微调、GraphRAG | 主题讨论、新颖性评估、摘要生成 知识库构建、多智能体协作 | |
| 星火科研助手[ | 预训练、有监督微调 基于人类反馈的强化学习 | 成果调研、综述生成、领域更新追踪 论文研读、多文档问答、研究方向推荐 |
表3
科技文献数据挖掘赋能LLMs的应用场景"
| 类型 | 场景 | 核心技术 | 典型案例 |
|---|---|---|---|
| 支撑构建通用大模型与垂直大模型 | 通用大模型 | 自监督学习、指令微调、迁移学习、RAG、基于人类反馈的强化学习、领域知识注入、提示工程 | PubScholar[ |
| 垂直领域大模型 | 星火科研助手[ | ||
| 支撑开发高质量数据集 | AI4S科技文献数据库 | 主动学习、RAG、提示工程 多智能体协作、领域知识注入 | 酶化学关系抽取数据集EnzChemRED[ |
| 支持AI驱动科学发现 | 假设生成 | 上下文学习、思维链提示 基于文献的发现、人机协作 | 科技文献知识驱动的AI引擎SciAIEngine[ |
| 实验验证 | 人工智能材料科学家MatPilot[ | ||
| 决策支持 | 公共生命科学数据语义整合知识库Euretos[ |
| 1 |
王飞跃, 缪青海. 人工智能驱动的科学研究新范式: 从AI4S到智能科学[J]. 中国科学院院刊, 2023, 38(4): 536-540.
|
|
|
|
| 2 |
李国杰. 智能化科研(AI4R): 第五科研范式[J]. 中国科学院院刊, 2024, 39(1): 1-9.
|
|
|
|
| 3 |
罗威, 谭玉珊. 基于内容的科技文献大数据挖掘与应用[J]. 情报理论与实践, 2021, 44(6): 154-157.
|
|
|
|
| 4 |
熊泽润, 宋立荣. 科学数据出版中同行评议的问题思考[J]. 中国科技资源导刊, 2022, 54(5): 21-29.
|
|
|
|
| 5 |
代冰, 胡正银. 基于文献的知识发现新近研究综述[J]. 数据分析与知识发现, 2021, 5(4): 1-12.
|
|
|
|
| 6 |
钱力, 张智雄, 伍大勇, 等. 科技文献大模型: 方法、框架与应用[J]. 中国图书馆学报, 2024, 50(6): 45-58.
|
|
|
|
| 7 |
支凤稳, 赵梦凡, 彭兆祺. 开放科学环境下科学数据与科技文献关联模式研究[J]. 数字图书馆论坛, 2023(10): 52-61.
|
|
|
|
| 8 |
李泽宇, 刘伟. 基于大语言模型全流程微调的叙词表等级关系构建研究[J]. 情报理论与实践, 2025, 48(4): 152-162.
|
|
|
|
| 9 |
曾建勋. “十四五”期间我国科技情报事业的发展思考[J]. 情报理论与实践, 2021, 44(1): 1-7.
|
|
|
|
| 10 |
|
| 11 |
赵冬晓, 王效岳, 白如江, 等. 面向情报研究的文本语义挖掘方法述评[J]. 现代图书情报技术, 2016(10): 13-24.
|
|
|
|
| 12 |
车万翔, 窦志成, 冯岩松, 等. 大模型时代的自然语言处理: 挑战、机遇与发展[J]. 中国科学: 信息科学, 2023, 53(9): 1645-1687.
|
|
|
|
| 13 |
张智雄, 于改红, 刘熠, 等. ChatGPT对文献情报工作的影响[J]. 数据分析与知识发现, 2023, 7(3): 36-42.
|
|
|
|
| 14 |
刘熠, 张智雄, 王宇飞, 等. 基于语步识别的科技文献结构化自动综合工具构建[J]. 数据分析与知识发现, 2024, 8(2): 65-73.
|
|
|
|
| 15 |
常志军, 钱力, 吴垚葶, 等. 面向主题场景的科技文献AI数据体系建设: 技术框架研究与实践[J]. 农业图书情报学报, 2024, 36(9): 4-17.
|
|
|
|
| 16 |
梁爽, 刘小平. 基于文本挖掘的科技文献主题演化研究进展[J]. 图书情报工作, 2022, 66(13): 138-149.
|
|
|
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
李盼飞, 杨小康, 白逸晨, 等. 基于大语言模型的中医医案命名实体抽取研究[J]. 中国中医药图书情报杂志, 2024, 48(2): 108-113.
|
|
|
|
| 24 |
杨冬菊, 黄俊涛. 基于大语言模型的中文科技文献标注方法[J]. 计算机工程, 2024, 50(9): 113-120.
|
|
|
|
| 25 |
|
| 26 |
|
| 27 |
陆伟, 刘寅鹏, 石湘, 等. 大模型驱动的学术文本挖掘: 推理端指令策略构建及能力评测[J]. 情报学报, 2024, 43(8): 946-959.
|
|
|
|
| 28 |
杨金庆, 吴乐艳, 魏雨晗, 等. 科技文献新兴话题识别研究进展[J]. 情报学进展, 2020, 13(00): 202-234.
|
|
|
|
| 29 |
|
| 30 |
|
| 31 |
杨帅, 刘建军, 金帆, 等. 人工智能与大数据在材料科学中的融合: 新范式与科学发现[J]. 科学通报, 2024, 69(32): 4730-4747.
|
|
|
|
| 32 |
|
| 33 |
|
| 34 |
|
| 35 |
|
| 36 |
|
| 37 |
|
| 38 |
|
| 39 |
|
| 40 |
Automating scientific knowledge extraction and modeling (ASKEM)[EB/OL]. [2025-01-14].
|
| 41 |
于丰畅, 程齐凯, 陆伟. 基于几何对象聚类的学术文献图表定位研究[J]. 数据分析与知识发现, 2021, 5(1): 140-149.
|
|
|
|
| 42 |
于丰畅, 陆伟. 一种学术文献图表位置标注数据集构建方法[J]. 数据分析与知识发现, 2020, 4(6): 35-42.
|
|
|
|
| 43 |
|
| 44 |
|
| 45 |
黄梓航, 陈令羽, 蒋秉川. 基于文本解析的栅格类图表知识抽取方法[J]. 地理空间信息, 2023, 21(10): 23-27.
|
|
|
|
| 46 |
|
| 47 |
琚江舟, 毛云麟, 吴震, 等. 多粒度单元格对比的文本和表格数值问答模型[J/OL]. 软件学报, 2024: 1-21.
|
|
|
|
| 48 |
容姿, 丁一, 李依泽, 等. 图表大数据解析方法综述[J]. 计算机辅助设计与图形学学报, 2025, 37(2): 216-228.
|
|
|
|
| 49 |
|
| 50 |
|
| 51 |
|
| 52 |
黎颖, 吴清锋, 刘佳桐, 等. 引导性权重驱动的图表问答重定位关系网络[J]. 中国图象图形学报, 2023, 28(2): 510-521.
|
|
|
|
| 53 |
|
| 54 |
|
| 55 |
周莉. 生成式人工智能对学术期刊的变革与赋能研究[J]. 黄冈师范学院学报, 2024, 44(6): 57-60.
|
|
|
|
| 56 |
|
| 57 |
|
| 58 |
|
| 59 |
姜鹏, 任龑, 朱蓓琳. 大语言模型在分类标引工作中的应用探索[J]. 农业图书情报学报, 2024, 36(5): 32-42.
|
|
|
|
| 60 |
|
| 61 |
|
| 62 |
马畅, 田永红, 郑晓莉, 等. 基于知识蒸馏的神经机器翻译综述[J]. 计算机科学与探索, 2024, 18(7): 1725-1747.
|
|
|
|
| 63 |
陈文杰, 胡正银, 石栖, 等. 融合知识图谱与大语言模型的科技文献复杂知识对象抽取研究[J/OL]. 现代情报, 2024: 1-20.
|
|
|
|
| 64 |
|
| 65 |
|
| 66 |
|
| 67 |
|
| 68 |
|
| 69 |
|
| 70 |
|
| 71 |
|
| 72 |
|
| 73 |
|
| 74 |
|
| 75 |
|
| 76 |
|
| 77 |
|
| 78 |
张智雄, 刘欢, 于改红. 构建基于科技文献知识的人工智能引擎[J]. 农业图书情报学报, 2021, 33(1): 17-31.
|
|
|
|
| 79 |
|
| 80 |
|
| 81 |
|
| 82 |
|
| 83 |
|
| 84 |
|
| 85 |
|
| 86 |
王译婧, 徐海静. 人工智能助力多模态档案资源开发的实现路径[J]. 山西档案, 2025(4): 120-126, 137.
|
|
|
|
| 87 |
王飞跃, 王雨桐. 数字科学家与平行科学: AI4S和S4AI的本源与目标[J]. 中国科学院院刊, 2024, 39(1): 27-33.
|
|
|
|
| 88 |
|
| 89 |
|
| 90 |
鲜国建, 罗婷婷, 赵瑞雪, 等. 从人工密集型到计算密集型: NSTL数据库建设模式转型之路[J]. 数字图书馆论坛, 2020(7): 52-59.
|
|
|
|
| 91 |
王婷, 何松泽, 杨川. 知识图谱相关方法在脑科学领域的应用综述[J]. 计算机技术与发展, 2022, 32(11): 1-7.
|
|
|
|
| 92 |
|
| 93 |
|
| 94 |
萧文科, 宋驰, 陈士林, 等. 中医药大语言模型的关键技术与构建策略[J]. 中草药, 2024, 55(17): 5747-5756.
|
|
|
|
| 95 |
|
| 96 |
|
| 97 |
|
| 98 |
|
| 99 |
|
| 100 |
|
| 101 |
孟小峰. 科学数据智能: 人工智能在科学发现中的机遇与挑战[J]. 中国科学基金, 2021, 35(3): 419-425.
|
|
|
|
| 102 |
高瑜蔚, 胡良霖, 朱艳华, 等. 国家基础学科公共科学数据中心建设与发展实践[J]. 科学通报, 2024, 69(24): 3578-3588.
|
|
|
|
| 103 |
邓仲华, 李志芳. 科学研究范式的演化: 大数据时代的科学研究第四范式[J]. 情报资料工作, 2013, 34(4): 19-23.
|
|
|
|
| 104 |
包为民, 祁振强. 航天装备体系化仿真发展的思考[J]. 系统仿真学报, 2024, 36(6): 1257-1272.
|
|
|
|
| 105 |
李正风. 当代科学的新变化与科学学的新趋向[J]. 世界科学, 2024(8): 41-44.
|
|
|
|
| 106 |
The Fourth Paradigm: Data-Intensive Scientific Discovery[M]. Redmond, WA: Microsoft Research, 2009.
|
| 107 |
余江, 张越, 周易. 人工智能驱动的科研新范式及学科应用研究[J]. 中国科学院院刊, 2025, 40(2): 362-370.
|
|
|
|
| 108 |
于改红, 谢靖, 张智雄, 等. 基于DIKIW的智能情报服务理论及系统框架研究与实践[J/OL]. 情报理论与实践, 2025: 1-11.
|
|
|
|
| 109 |
张智雄. 在开放科学和AI时代塑造新型学术交流模式[J]. 中国科技期刊研究, 2024, 35(5): 561-567.
|
|
|
|
| 110 |
钱力, 刘细文, 张智雄, 等. AI+智慧知识服务生态体系研究设计与应用实践: 以中国科学院文献情报中心智慧服务平台建设为例[J]. 图书情报工作, 2021, 65(15): 78-90.
|
|
|
|
| 111 |
|
| 112 |
|
| 113 |
|
| 114 |
|
| 115 |
周力虹. 面向驱动AI4S的科学数据聚合: 需求、挑战与实现路径[J]. 农业图书情报学报, 2023, 35(10): 13-15.
|
|
|
|
| 116 |
叶悦. AI大模型时代出版内容数据保护的理据与进路[J]. 出版与印刷, 2025(1): 27-36.
|
|
|
|
| 117 |
|
| [1] | 吕璐成, 周健, 孙文君, 赵亚娟, 韩涛. 微调大模型在专利文本挖掘中的应用效果研究[J]. 农业图书情报学报, 2026, 38(4): 36-46. |
| [2] | 钱力, 杨颜僖, 张元哲, 胡懋地, 常志军. OpenClaw对科技文献情报工作的影响与启示[J]. 农业图书情报学报, 2026, 38(4): 4-12. |
| [3] | 吴玉浩, 刘艺浩, 李庆军, 胡旭. 基于大语言模型的图书馆数据开放共享:逻辑、路径与策略[J]. 农业图书情报学报, 2026, 38(1): 28-43. |
| [4] | 王晓宇, 胡靖源, 巫若羽, 王舒, 翟羽佳. 基于大语言模型数据增强的“科学-技术”主题关联方法研究——以节能领域为例[J]. 农业图书情报学报, 2025, 37(9): 63-81. |
| [5] | 翟军, 孟子涵, 李方苏, 沈立新. AI4S背景下北美研究型图书馆AI指南研究——基于对125所ARL图书馆的调研[J]. 农业图书情报学报, 2025, 37(7): 35-49. |
| [6] | 张丽, 王博, 张琪晶. 生成式人工智能驱动公共图书馆资源发现:基于动态评价模型的服务优化研究[J]. 农业图书情报学报, 2025, 37(5): 58-71. |
| [7] | 钱力, 王茜颖, 刘熠, 张元哲, 常志军. 科研场景下的智能体技术与应用研究[J]. 农业图书情报学报, 2025, 37(5): 5-14. |
| [8] | 刘炜, 张磊, 嵇婷, 陈晓扬. 以AI塑形智慧图书馆:基于智能体的下一代图书馆服务平台[J]. 农业图书情报学报, 2025, 37(5): 15-26. |
| [9] | 乔晋华, 马雪赟. LLaMA人工智能大模型在高校未来学习中心应用的风险与规制[J]. 农业图书情报学报, 2025, 37(2): 37-48. |
| [10] | 李鑫鑫, 马雨萌, 鞠孜涵, 王敬. 基于大语言模型的科技政策评论方面级情感分析研究——以新能源汽车产业为例[J]. 农业图书情报学报, 2025, 37(10): 53-66. |
| [11] | 王昊贤, 周子茗, 丁菲菲, 韦成府. 数字人文与大语言模型:古文献语义检索实践与探索[J]. 农业图书情报学报, 2024, 36(9): 89-101. |
| [12] | 姜鹏, 任龑, 朱蓓琳. 大语言模型在分类标引工作中的应用探索[J]. 农业图书情报学报, 2024, 36(5): 32-42. |
| [13] | 寿建琪. 走向“已知之未知”:GPT大语言模型助力实现以人为本的信息检索[J]. 农业图书情报学报, 2023, 35(5): 16-26. |
| [14] | 郭鹏睿, 文庭孝. 大语言模型对信息检索系统与用户检索行为影响研究[J]. 农业图书情报学报, 2023, 35(11): 13-22. |
| [15] | 孙坦, 张智雄, 周力虹, 王东波, 张海, 李白杨, 勇素华, 左旺孟, 杨光磊. 人工智能驱动的第五科研范式(AI4S)变革与观察[J]. 农业图书情报学报, 2023, 35(10): 4-32. |
|
||


