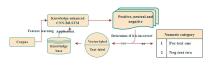
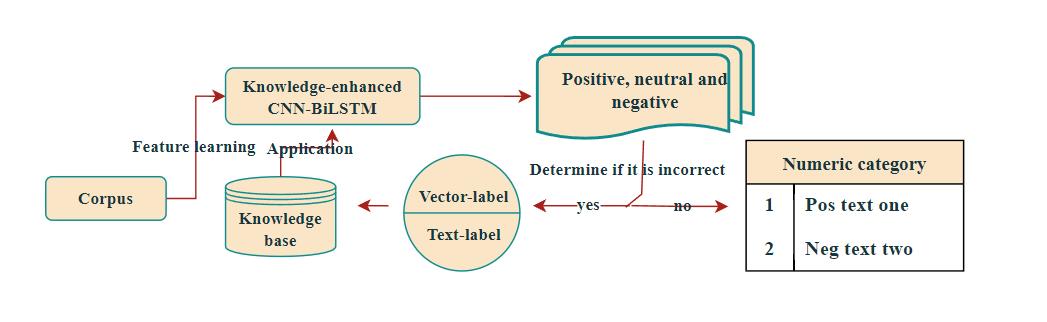
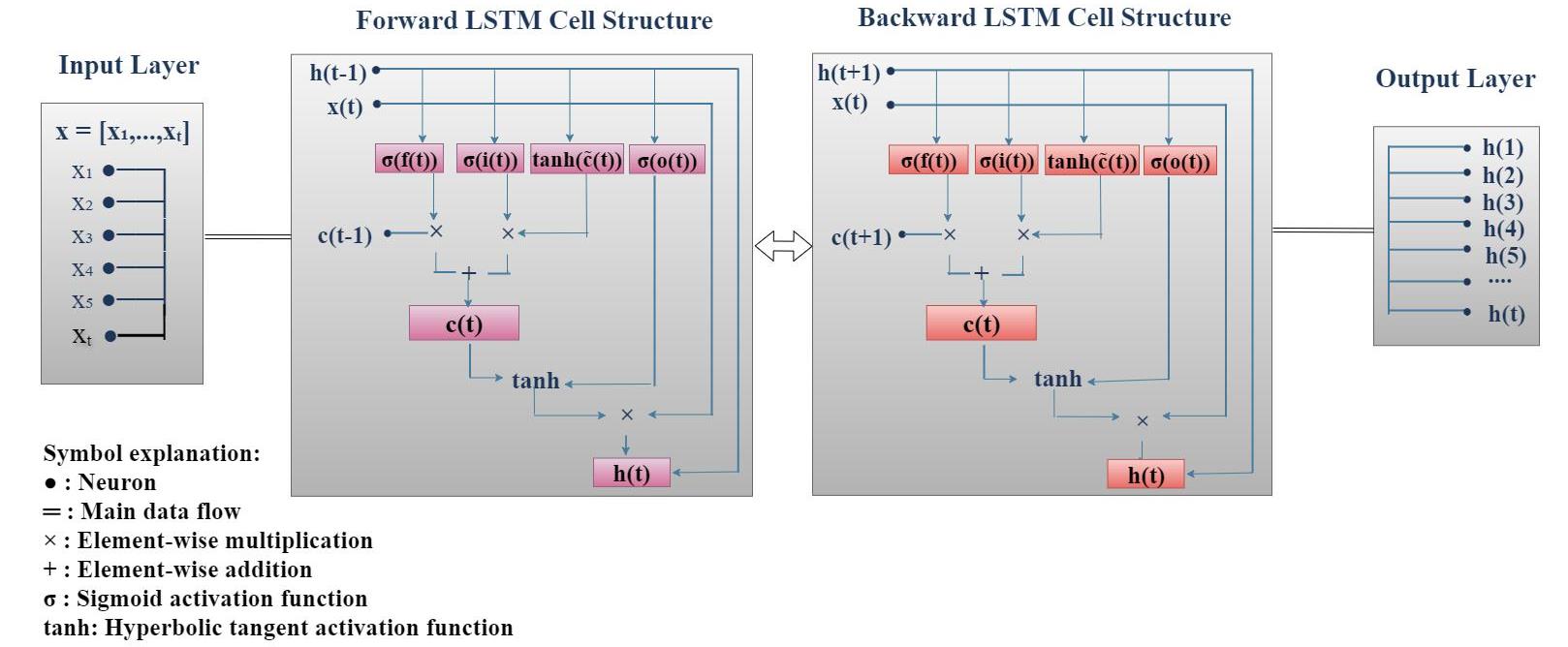
| [1] |
LIU X, LI F, XIAO W. Measuring linguistic complexity in Chinese: An information-theoretic approach[J]. Humanities and social sciences communications, 2024, 11: 980.
|
| [2] |
PICKREN S E, STACY M, DEL TUFO S N, et al. The contribution of text characteristics to reading comprehension: Investigating the influence of text emotionality[J]. Reading research quarterly, 2022, 57(2): 649-667.
|
| [3] |
HALLIDAY M A K, MATTHIESSEN C M I M. Halliday's introduction to functional grammar[M]. London: Routledge, 2014.
|
| [4] |
MIESTAMO M, SINNEMÄKI K, KARLSSON F. Language complexity: Typology, contact, change[M]. Amsterdam: John Benjamins Publishing, 2008.
|
| [5] |
SWELLER J, VAN MERRIENBOER J J G, PAAS F G W C. Cognitive architecture and instructional design[J]. Educational psychology review, 1998, 10(3): 251-296.
|
| [6] |
BENJAMIN R G. Reconstructing readability: Recent developments and recommendations in the analysis of text difficulty[J]. Educational psychology review, 2012, 24(1): 63-88.
|
| [7] |
WANG Y X, BERWICK R C, LUO X F, et al. A formal measurement of the cognitive complexity of texts in cognitive linguistics[C]//2012 IEEE 11th International Conference on Cognitive Informatics and Cognitive Computing. August 22-24, 2012, Kyoto, Japan. IEEE, 2012: 94-102.
|
| [8] |
WANG X Z, KOU L Y, SUGUMARAN V, et al. Emotion correlation mining through deep learning models on natural language text[J]. IEEE transactions on cybernetics, 2021, 51(9): 4400-4413.
|
| [9] |
ZENG J C, LI J, SONG Y, et al. Topic memory networks for short text classification[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium. Stroudsburg, PA, USA: ACL, 2018: 3120-3131.
|
| [10] |
ZHANG Y H, ZHANG Y, GUO W Y, et al. Learning disentangled representation for multimodal cross-domain sentiment analysis[J]. IEEE transactions on neural networks and learning systems, 2023, 34(10): 7956-7966.
|
| [11] |
CHEN J D, HU Y Z, LIU J P, et al. Deep short text classification with knowledge powered attention[C]//Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence. ACM, 2019: 6252-6259.
|
| [12] |
MINAEE S, KALCHBRENNER N, CAMBRIA E, et al. Deep learning: Based text classification: A comprehensive review[J]. ACM computing surveys, 2021, 54(3): 1-40.
|
| [13] |
WANG Q L, WEN Z Y, DING K Y, et al. Cross-domain sentiment analysis via disentangled representation and prototypical learning[J]. IEEE transactions on affective computing, 2025, 16(1): 264-276.
|
| [14] |
DENG Y, ZHANG W X, PAN S J, et al. Bidirectional generative framework for cross-domain aspect-based sentiment analysis[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada. Stroudsburg, PA, USA: ACL, 2023: 12272-12285.
|
| [15] |
TIWARI D, NAGPAL B. KEAHT: A knowledge-enriched attention-based hybrid transformer model for social sentiment analysis[J]. New generation computing, 2022, 40(4): 1165-1202.
|
| [16] |
LARSEN–FREEMAN D. On language learner agency: A complex dynamic systems theory perspective[J]. The modern language journal, 2019, 103(S1): 61-79.
|
| [17] |
LAUDAŃSKA Z, CAUNT A, CRISTIA A, et al. From data to discovery: Technology propels speech-language research and theory-building in developmental science[J]. Neuroscience & biobehavioral reviews, 2025, 174: 106199.
|
| [18] |
ELLIS N C. Essentials of a theory of language cognition[J]. The modern language journal, 2019, 103(S1): 39-60.
|
| [19] |
TAN H Z, XU C P, LI J, et al. HICL: Hashtag-driven in-context learning for social media natural language understanding[J]. IEEE transactions on neural networks and learning systems, 2025, 36(4): 7037-7050.
|
| [20] |
HUANG F L, LI X L, YUAN C G, et al. Attention-emotion-enhanced convolutional LSTM for sentiment analysis[J]. IEEE transactions on neural networks and learning systems, 2022, 33(9): 4332-4345.
|
| [21] |
NORTH K, ZAMPIERI M, SHARDLOW M. Lexical complexity prediction: An overview[J]. ACM computing surveys, 2023, 55(9): 1-42.
|
| [22] |
ZHANG X P, LU X F. Revisiting the predictive power of traditional vs. fine-grained syntactic complexity indices for L2 writing quality: The case of two genres[J]. Assessing writing, 2022, 51: 100597.
|
| [23] |
WANG W K, CHEN G H, WANG H Q, et al. Multilingual sentence transformer as a multilingual word aligner[C]//Findings of the Association for Computational Linguistics: EMNLP 2022. Abu Dhabi, United Arab Emirates. Stroudsburg, PA, USA: ACL, 2022: 2952-2963.
|
| [24] |
BARZILAY R, LAPATA M. Modeling local coherence: An entity-based approach[J]. Computational linguistics, 2008, 34(1): 1-34.
|
| [25] |
BLITZER J, DREDZE M, PEREIRA F C. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification[C]//Annual Meeting of the Association for Computational Linguistics., 2007
|
| [26] |
PAN S J, TSANG I W, KWOK J T, et al. Domain adaptation via transfer component analysis[J]. IEEE transactions on neural networks, 2011, 22(2): 199-210.
|
| [27] |
GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation[EB/OL]. 2014: arXiv: 1409.7495.
|
| [28] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]//North American Chapter of the Association for Computational Linguistics., 2019
|
| [29] |
LIU W J, ZHOU P, ZHAO Z, et al. K-BERT: Enabling language representation with knowledge graph[J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(3): 2901-2908.
|
| [30] |
KE P, JI H Z, LIU S Y, et al. SentiLARE: Sentiment-aware language representation learning with linguistic knowledge[EB/OL]. 2019: arXiv: 1911.02493.
|
| [31] |
SUN Y, WANG S H, LI Y K, et al. ERNIE: Enhanced representation through knowledge integration[EB/OL]. 2019: arXiv: 1904.09223.
|
| [32] |
PETERS M E, NEUMANN M, LOGAN R, et al. Knowledge enhanced contextual word representations[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China. Stroudsburg, PA, USA: ACL, 2019: 43-54.
|
| [33] |
SU Y S, HAN X, ZHANG Z Y, et al. CokeBERT: Contextual knowledge selection and embedding towards enhanced pre-trained language models[J]. AI open, 2021, 2: 127-134.
|
| [34] |
KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the national academy of sciences of the United States of America, 2017, 114(13): 3521-3526.
|
| [35] |
RAMSHANKAR N, P M J P. Automated sentimental analysis using heuristic-based CNN-BiLSTM for E-commerce dataset[J]. Data & knowledge engineering, 2023, 146: 102194.
|
| [36] |
ALLAM E G, MADBOULY M M, GUIRGUIS S K. Arabic language sentiment analysis using feature engineering and deep learning RNN-LSTM framework[C]//2021 31st International Conference on Computer Theory and Applications (ICCTA). Alexandria, Egypt. IEEE, 2022: 160-165.
|
| [37] |
HAN K, WANG Y H, CHEN H T, et al. A survey on vision transformer[J]. IEEE transactions on pattern analysis and machine intelligence, 2023, 45(1): 87-110.
|
| [38] |
TAY Y, DEHGHANI M, BAHRI D, et al. Efficient transformers: A survey[J]. ACM computing surveys, 2022, 55(6): 1-28.
|
| [39] |
WU H G, KONG D L, WANG L J, et al. Multimodal sentiment analysis method based on image-text quantum transformer[J]. Neurocomputing, 2025, 637: 130107.
|