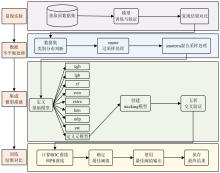
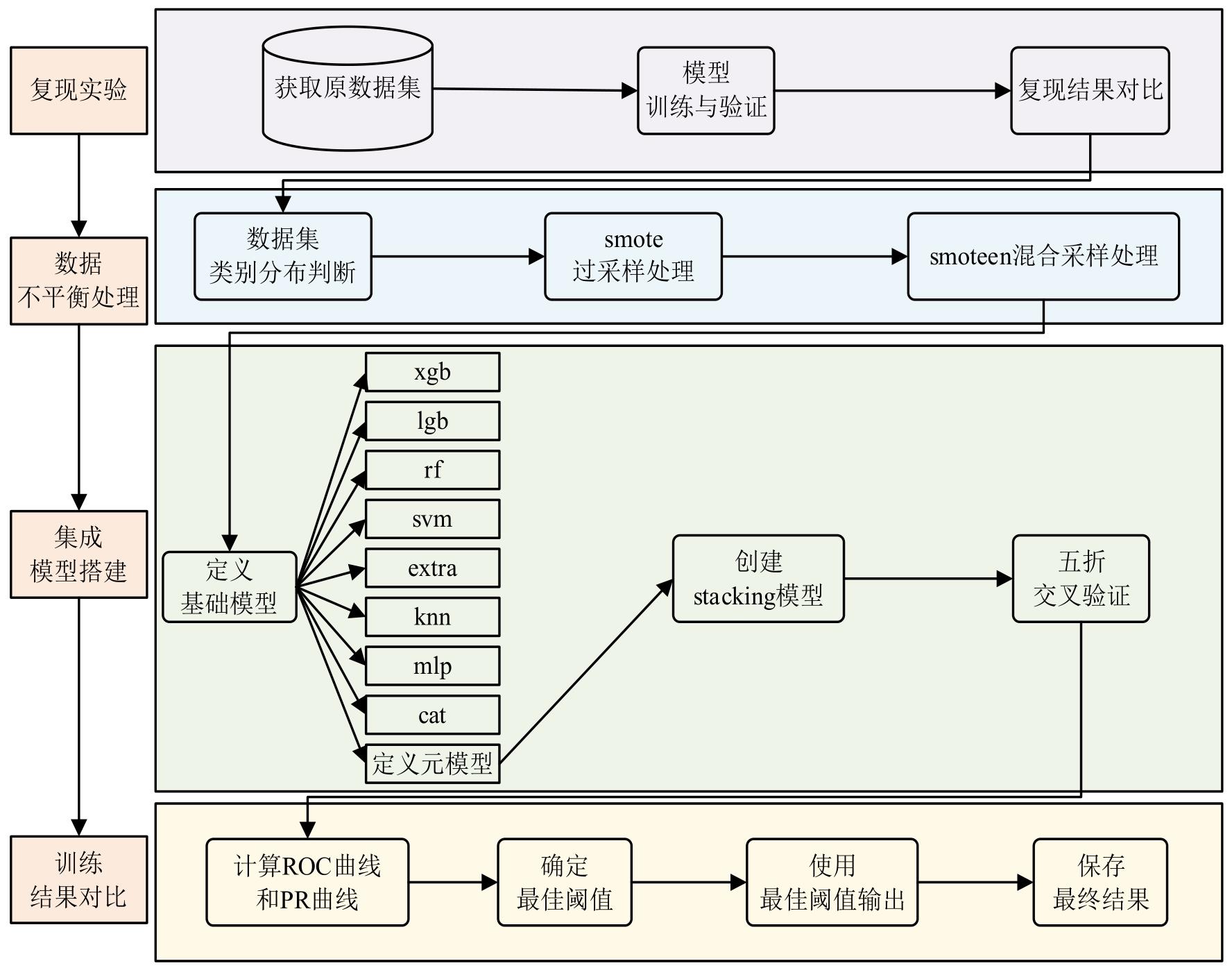
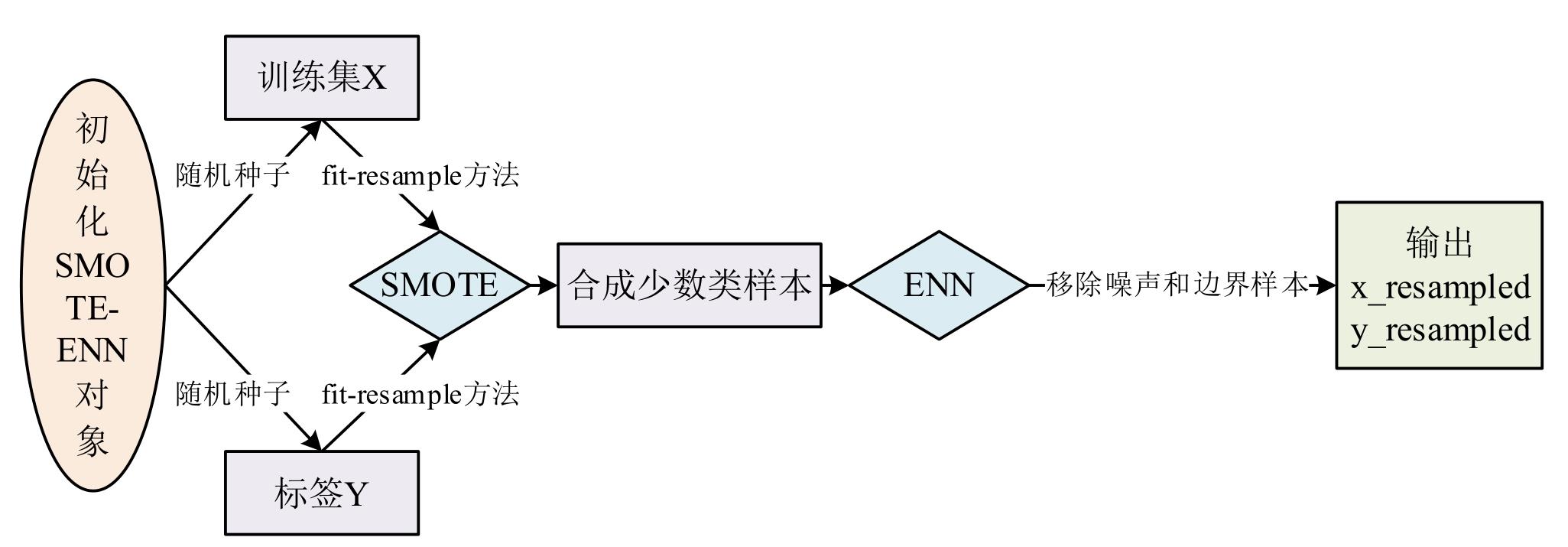
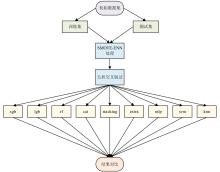
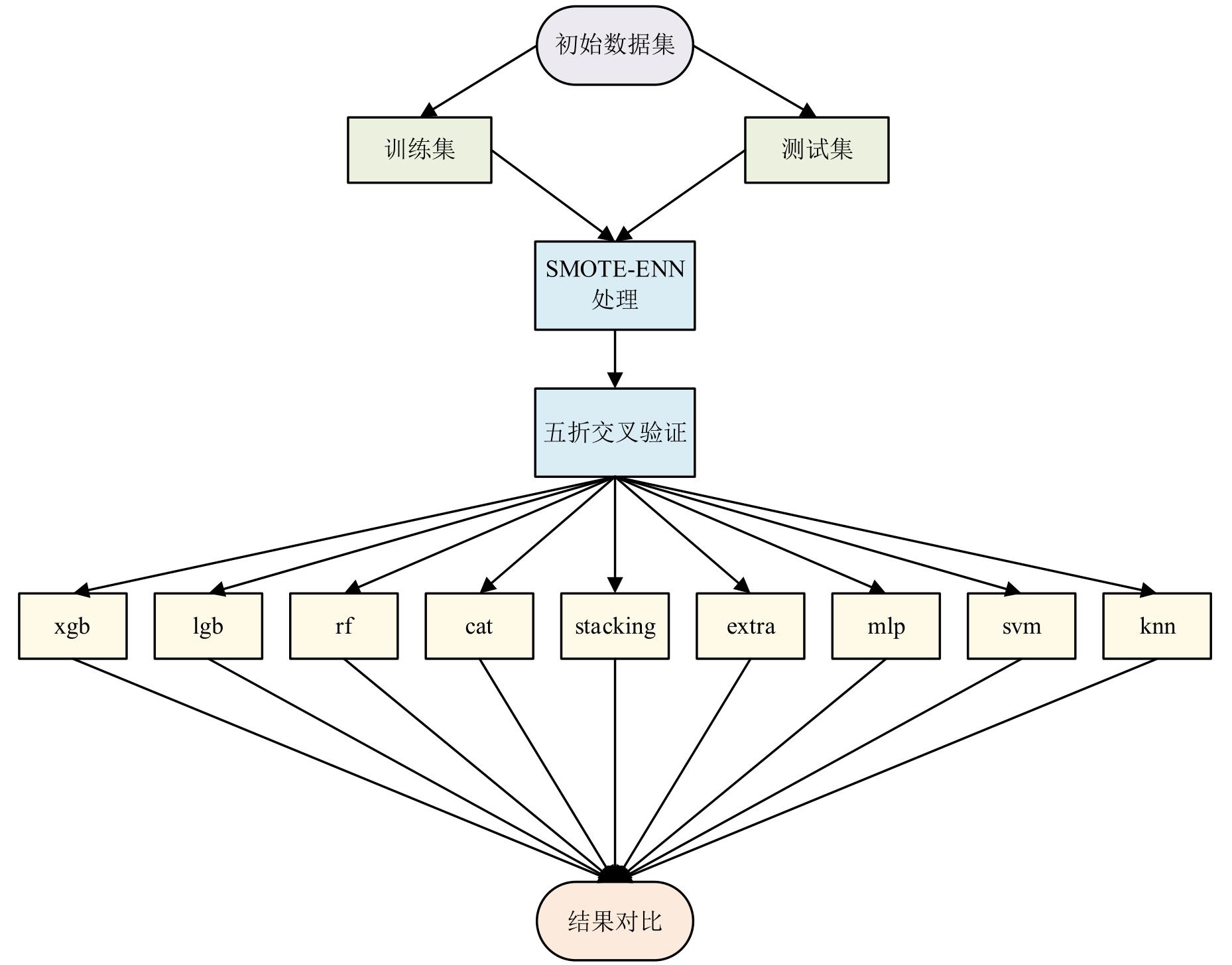
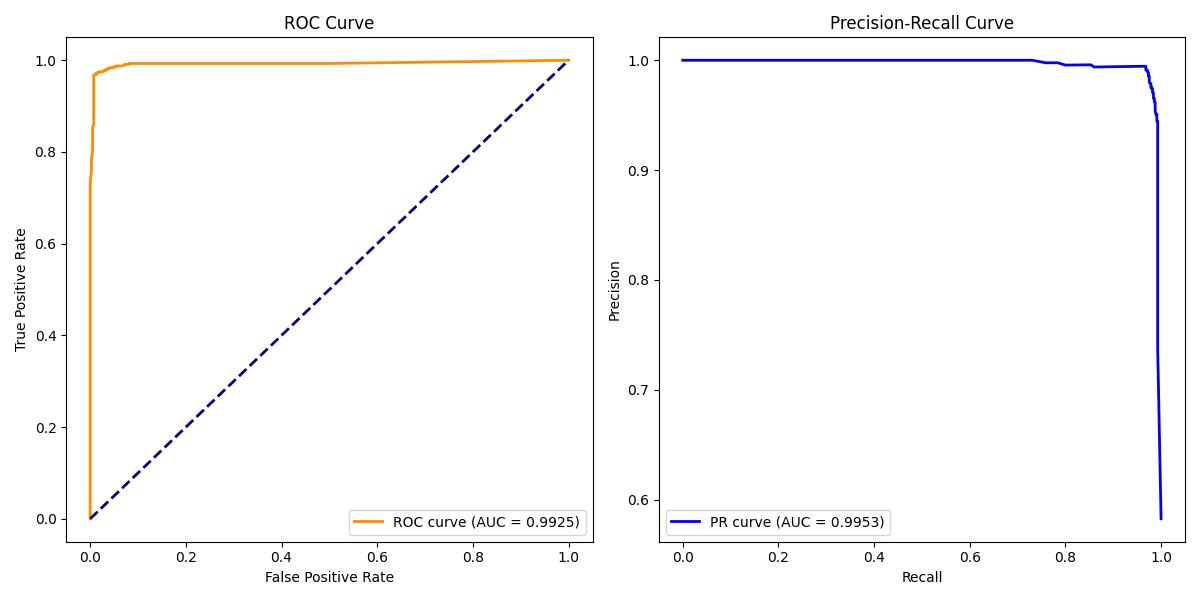
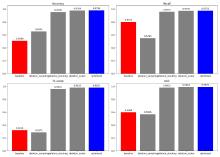
| [1] |
Christensen C M. The Innovator's Dilemma[M]. Boston, Mass.: Harvard Business School Press, 1997.
|
| [2] |
中国科学院颠覆性技术创新研究组. 颠覆性技术创新研究-生命科学领域[M]. 北京: 科学出版社, 2020.
|
| [3] |
Sommarberg M, Mäkinen S J. A method for anticipating the disruptive nature of digitalization in the machine-building industry[J]. Technological Forecasting and Social Change, 2019, 146: 808-819.
|
| [4] |
白光祖, 郑玉荣, 吴新年, 等. 基于文献知识关联的颠覆性技术预见方法研究与实证[J]. 情报杂志, 2017, 36(9): 38-44.
|
|
Bai Guangzu, Zheng Yurong, Wu Xinnian, et al. Research and demonstration on forecasting method of disruptive technology based on literature knowledge correlation[J]. Journal of Intelligence, 2017, 36(9): 38-44.
|
| [5] |
王知津, 周鹏, 韩正彪. 基于情景分析法的技术预测研究[J]. 图书情报知识, 2013, 30(5): 115-122.
|
|
Wang Zhijin, Zhou Peng, Han Zhengbiao. A study of the technological forecasting based on scenario analysis[J]. Documentation, Information & Knowledge, 2013, 30(5): 115-122.
|
| [6] |
曹悦, 白晨, 张英杰, 等. 颠覆性技术识别模型研究——以工业机器人领域为例[J]. 中国科技资源导刊, 2022, 54(2): 81-92.
|
|
Cao Yue, Bai Chen, Zhang Yingjie, et al. Research on disruptive technology recognition model - Taking industrial robots as an example[J]. China Science & Technology Resources Review, 2022, 54(2): 81-92.
|
| [7] |
陈育新, 卢俊, 韩毅. 基于专利文献的颠覆性技术识别研究——以人工智能为例[J]. 情报学报, 2022, 41(11): 1124-1133.
|
|
Chen Yuxin, Lu Jun, Han Yi. Topic prediction for disruptive technologies based on patent literature - A case study of artificial intelligence patents[J]. Journal of the China Society for Scientific and Technical Information, 2022, 41(11): 1124-1133.
|
| [8] |
刘雨农, 石静, 梁琴琴. 基于STM的颠覆性技术主题识别研究[J]. 情报工程, 2023, 9(3): 81-91.
|
|
Liu Yunong, Shi Jing, Liang Qinqin. STM-based topic identification for disruptive technologies[J]. Technology Intelligence Engineering, 2023, 9(3): 81-91.
|
| [9] |
赵一鸣, 刘顺生, 吕璐成. 基于集成学习的颠覆性技术早期识别研究——以量子计算领域为例[J]. 数据分析与知识发现, 2025, 9(10): 85-98.
|
|
Zhao Yiming, Liu Shunsheng, Lucheng Lyu. Early identification of disruptive technologies with ensemble learning: Case study in quantum computing[J]. Data Analysis and Knowledge Discovery, 2025, 9(10): 85-98.
|
| [10] |
王莉晓, 陈伟, 邱含琪. 基于机器学习的颠覆性技术弱信号识别模型研究[J]. 数据分析与知识发现, 2024, 8(8): 63-75.
|
|
Wang Lixiao, Chen Wei, Qiu Hanqi. Weak signal identification model for disruptive technologies based on machine learning[J]. Data Analysis and Knowledge Discovery, 2024, 8(8): 63-75.
|
| [11] |
徐硕, 李静鸿, 安欣. 基于专利术语的颠覆性技术识别及实证研究[J]. 图书情报工作, 2024, 68(2): 62-72.
|
|
Xu Shuo, Li Jinghong, An Xin. Disruptive technology identification and empirical study on the basis of patent terms[J]. Library and Information Service, 2024, 68(2): 62-72.
|
| [12] |
唐虎林, 苏成, 李旺雨. 基于系统思维的颠覆性技术弱信号分析理论研究[J]. 情报学报, 2025, 44(4): 398-413.
|
|
Tang Hulin, Su Cheng, Li Wangyu. Theoretical research on the weak signal analysis of disruptive technology based on system thinking[J]. Journal of the China Society for Scientific and Technical Information, 2025, 44(4): 398-413.
|
| [13] |
Li Ran, Yu Wangke, Huang Qianliang, et al. A new identify disruptive technologies algorithm based on technology develop network[J]. Mathematical Problems in Engineering, 2022, 2022(1): 7354535.
|
| [14] |
Vojak B A, Chambers F A. Roadmapping disruptive technical threats and opportunities in complex, technology-based subsystems: The SAILS methodology[J]. Technological Forecasting and Social Change, 2004, 71(1/2): 121-139.
|
| [15] |
Walsh S T, Boylan R L, McDermott C, et al. The semiconductor silicon industry roadmap: Epochs driven by the dynamics between disruptive technologies and core competencies[J]. Technological Forecasting and Social Change, 2005, 72(2): 213-236.
|
| [16] |
王燕鹏, 王学昭. 技术突破和场景牵引视角下颠覆性技术量化识别方法研究[J]. 情报理论与实践, 2025, 48(3): 143-150, 159.
|
|
Wang Yanpeng, Wang Xuezhao. Research on quantitative identification method of disruptive technology from the perspective of technological breakthrough and scenario traction[J]. Information Studies (Theory & Application), 2025, 48(3): 143-150, 159.
|
| [17] |
李乾瑞, 郭俊芳, 黄颖, 等. 基于突变-融合视角的颠覆性技术主题演化研究[J]. 科学学研究, 2021, 39(12): 2129-2139.
|
|
Li Qianrui, Guo Junfang, Huang Ying, et al. Topic evolution research of disruptive technology based on mutation and fusion perspective[J]. Studies in Science of Science, 2021, 39(12): 2129-2139.
|
| [18] |
冯立杰, 秦浩, 王金凤, 等. 融合专利数据与社交媒体数据的潜在颠覆性技术识别——基于深度学习模型[J]. 情报学报, 2024, 43(2): 181-197.
|
|
Feng Lijie, Qin Hao, Wang Jinfeng, et al. A deep learning approach for identification of potentially disruptive technologies by integrating patent data and social media[J]. Journal of the China Society for Scientific and Technical Information, 2024, 43(2): 181-197.
|
| [19] |
Dotsika F, Watkins A. Identifying potentially disruptive trends by means of keyword network analysis[J]. Technological Forecasting and Social Change, 2017, 119: 114-127.
|
| [20] |
夏若雨. 基于多源数据的颠覆性技术识别方法研究[D]. 绵阳: 西南科技大学, 2024.
|
|
Xia Ruoyu. Research on Disruptive Technology Identification Based on Multisource Data[D]. Mianyang: Southwest University of Science and Technology, 2024.
|
| [21] |
王海军, 于佳文. 基于专利和微博的颠覆性技术主题识别研究——以人工智能领域为例[J]. 中国科技论坛, 2024(7): 83-94, 109.
|
|
Wang Haijun, Yu Jiawen. Identification research on disruptive technology topics based on patents and microblogging - A artificial intelligence industry case[J]. Forum on Science and Technology in China, 2024(7): 83-94, 109.
|
| [22] |
Xu Xueming, Li Jichao, Jiang Jiang, et al. A disruptive technology identification method based on multisource data: Take unmanned aerial vehicle systems as an example[C]//2021 7th International Conference on Big Data and Information Analytics (BigDIA). Piscataway, New Jersey: IEEE, 2021: 428-435.
|
| [23] |
Liu Xiwen, Wang Xuezhao, Lucheng Lyu, et al. Identifying disruptive technologies by integrating multi-source data[J]. Scientometrics, 2022, 127(9): 5325-5351.
|
| [24] |
马晓迪. 基于机器学习的潜在颠覆性技术识别方法研究[D]. 北京: 北京工业大学, 2023.
|
|
Ma Xiaodi. Research on Potential Disruptive Technology Identification Methods Based on Machine Learning[D]. Beijing: Beijing University of Technology, 2023.
|
| [25] |
Li Xin, Ma Xiaodi. Early identification of potential disruptive technologies using machine learning and text mining[C]//2023 Portland International Conference on Management of Engineering and Technology (PICMET). Piscataway, New Jersey: IEEE, 2023: 1-15.
|
| [26] |
Chen Xiaoli, Han Tao. Disruptive technology forecasting based on gartner hype cycle[C]//2019 IEEE Technology & Engineering Management Conference (TEMSCON). Piscataway, New Jersey: IEEE, 2019: 1-6.
|
| [27] |
范明姐. 基于多源异构数据的颠覆性技术早期识别研究[D]. 北京: 北京工业大学, 2020.
|
|
Fan Mingjie. Early Identification of Disruptive Technology Based on Multi-Source Heterogeneous Data[D]. Beijing: Beijing University of Technology, 2020.
|
| [28] |
王萌萌, 吴艾晗, 邓琨升, 等. 基于学科交叉驱动的颠覆性技术预测研究[J]. 情报杂志, 2025, 44(3): 72-80, 138.
|
|
Wang Mengmeng, Wu Aihan, Deng Kunsheng, et al. Research on predicting disruptive technology driven by interdisciplinarity[J]. Journal of Intelligence, 2025, 44(3): 72-80, 138.
|
| [29] |
马亚雪, 王嘉杰, 巴志超, 等. 颠覆性技术的后向科学引文知识特征识别研究——以基因工程领域为例[J]. 图书情报工作, 2024, 68(1): 116-126.
|
|
Ma Yaxue, Wang Jiajie, Ba Zhichao, et al. Research on the knowledge feature identification of disruptive technologies from its backward scientific citations: Taking the field of genetic engineering as an example[J]. Library and Information Service, 2024, 68(1): 116-126.
|
| [30] |
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357.
|
| [31] |
Wilson D L. Asymptotic properties of nearest neighbor rules using edited data[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1972, SMC-2(3): 408-421.
|
| [32] |
张高源, 赵瑞青, 张岩波, 等. 基于SMOTE-ENN结合改进动态集成选择算法构建DLBCL患者2年内复发预测模型[J]. 中国卫生统计, 2025, 42(1): 50-55, 61.
|
|
Zhang Gaoyuan, Zhao Ruiqing, Zhang Yanbo, et al. Recurrence prediction model of DLBCL patients within 2 years based on SMOTE-ENN combined with improved dynamic ensemble selection algorithm[J]. Chinese Journal of Health Statistics, 2025, 42(1): 50-55, 61.
|
| [33] |
Wolpert D H. Stacked generalization[J]. Neural Networks, 1992, 5(2): 241-259.
|
| [34] |
Nemet G F, Husmann D. PV learning curves and cost dynamics[M]//Advances in Photovoltaics: Volume 1. Amsterdam: Elsevier, 2012: 85-142.
|
| [35] |
Sun Bixuan, Kolesnikov S, Goldstein A, et al. A dynamic approach for identifying technological breakthroughs with an application in solar photovoltaics[J]. Technological Forecasting and Social Change, 2021, 165(C): 120534
|