

0 引言
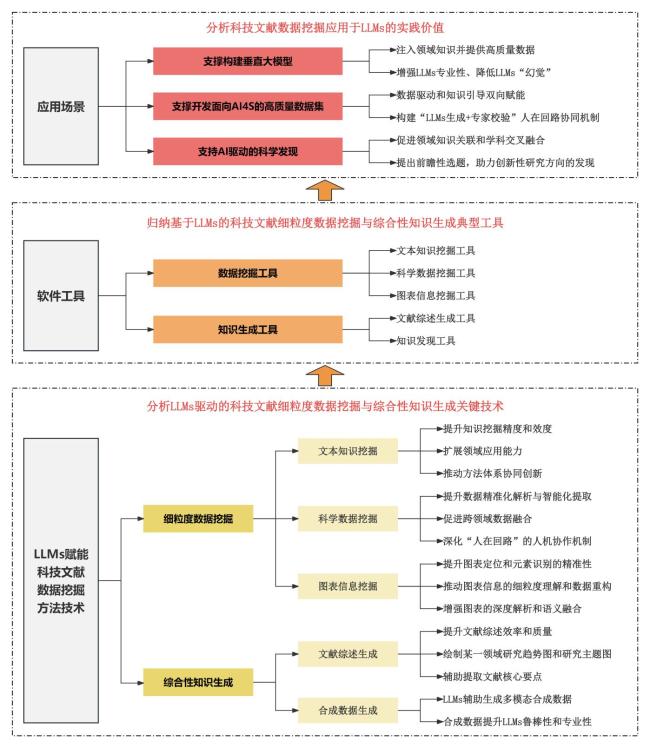
1 LLMs赋能科技文献数据挖掘的方法技术
1.1 基于LLMs的科技文献细粒度数据挖掘
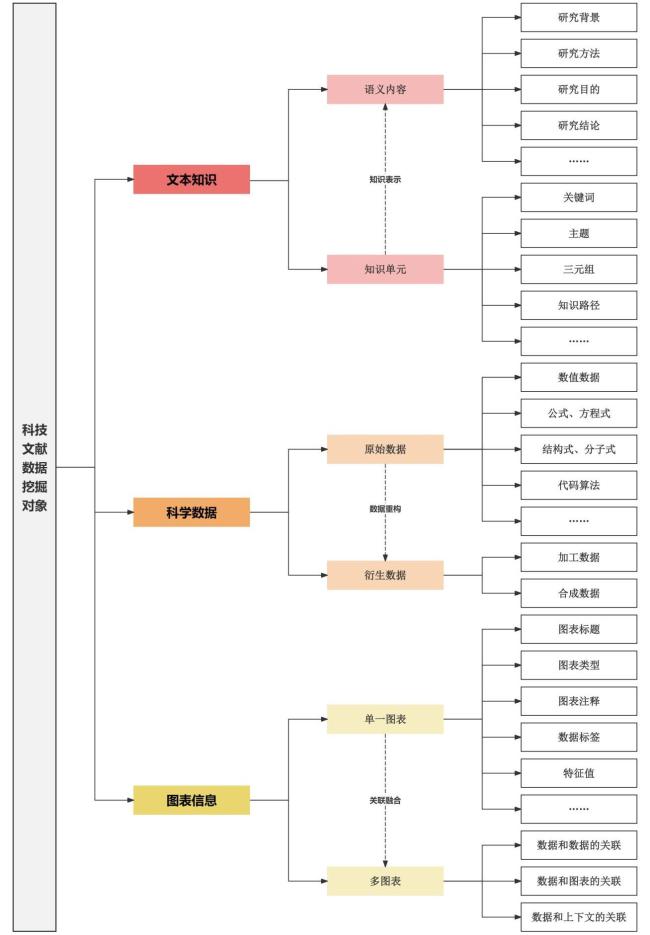
1.1.1 面向文本知识的挖掘
1.1.2 面向科学数据的挖掘
1.1.3 面向图表信息的挖掘
1.2 基于LLMs的科技文献综合性知识生成
1.2.1 LLMs辅助文献综述
1.2.2 LLMs辅助合成数据生成
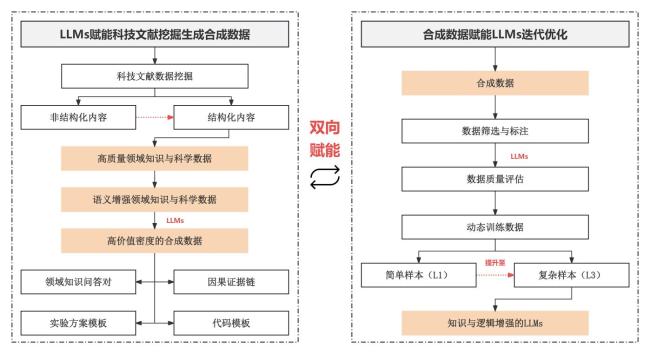
图3 科技文献合成数据与LLMs双向赋能框架Fig.3 Bidirectional empowerment framework of scientific literature synthetic data and large language models |
表1 基于大语言模型的科技文献数据挖掘和知识生成方法技术Table 1 Methods of data mining and knowledge discovery in scientific literature using large language models |
| 类别 | 功能 | 方法技术 |
|---|---|---|
| 数据挖掘 | 文本知识挖掘 | 上下文学习[17,27,50]、少样本提示[19,21,22,26]、零样本提示[24,25]、思维链提示[27] 工具调用与API集成[18,70]、GraphRAG[24]、微调[18,26]、预训练[18,20-22]、RAG[71] |
| 科学数据挖掘 | 思维链提示[29,34]、GraphRAG[39]、微调[30,72]、主动学习[36,39,40,70]、自动推理与规划[32,34] | |
| 图表信息挖掘 | 上下文学习[50]、预训练[46,47,50]、卷积循环神经网络[44,45]、深度神经网络[46]、注意力机制[44] | |
| 知识生成 | 文献综述生成 | 少样本提示[54]、RAG[18,53,54,58]、微调[18,71] |
| 合成数据生成 | 上下文学习[26,68]、少样本提示[26,73]、GraphRAG[63,64]、自动推理与规划[32,34]、微调[26,33] |
*注:GraphRAG即基于图的检索增强生成(Graph-Based Retrieval-Augmented Generation) |
2 LLMs赋能科技文献数据挖掘的软件工具
表2 大语言模型赋能科技文献数据挖掘的典型工具Table 2 Typical tools for data mining in scientific literature using large language models |
| 类型 | 功能 | 工具名称 | 方法技术 | 应用场景 |
|---|---|---|---|---|
| 数据挖掘 | 文本知识挖掘 | LitAI[74] | OCR、上下文学习、 少样本提示、思维链提示 | 文本抽取和结构化、文本质量增强 文本分类、纠正语法错误、参考文献管理 |
| GOT-OCR2.0[75] | 注意力机制、上下文学习 多阶段预训练、指令微调 | 文本识别、文档数字化 | ||
| SciAIEngine[78] | 自然语言处理、少样本提示、提示工程 | 语步识别、命名实体识别 科技文献挖掘、深度聚类等 | ||
| MDocAgent[83] | OCR、RAG 上下文学习、GraphRAG | 多模态数据融合、文本识别和抽取、文档问答 | ||
| LongDocURL[84] | 特征融合、RAG、OCR | 长文档解析、文档问答 | ||
| 科学数据挖掘 | LitAI[74] | OCR、上下文学习 少样本提示、思维链提示 | 科学数据抽取 | |
| MinerU | 上下文学习、多模态融合 基于人类反馈的强化学习 | 多模态科学数据挖掘 数字公式识别、方程式分子结构式挖掘 | ||
| TableGPT2[85] | 注意力机制、神经网络架构 | 表格数据理解、数据管理、数据计算分析 | ||
| GOT-OCR2.0[75] | 注意力机制、上下文学习 多阶段预训练、指令微调 | 数字公式识别、方程式分子结构式挖掘 | ||
| olmOCR[76] | OCR、文档锚定、微调、思维链提示 | 数字公式识别、方程式分子结构式挖掘 | ||
| 图表信息挖掘 | LitAI[74] | OCR、上下文学习 少样本提示、思维链提示 | 图注抽取与解释、图像数据与文本数据关联 图表语义增强 | |
| olmOCR[76] | OCR、微调、思维链提示 | 表格识别、提取图表中的关键数据点 | ||
| 知识生成 | 文献综述生成 | Agent Laboratory[80] | 思维链提示、基于Transformer架构 | 文献综述、实验设计与分析 代码生成、结果解释、报告撰写 |
| Web of Science研究助手 | 上下文学习、思维链提示 | 文献综述、期刊推荐、数据可视化 | ||
| SciAIEngine[78] | 自然语言处理、少样本提示、提示工程 | 文本标题生成、结构化自动综述 | ||
| Deep Research | 自然语言处理、端到端强化学习 | 文献综述、论文润色、生成报告 | ||
| AutoSurvey[54] | RAG、提示工程、词嵌入 | 初始检索与大纲生成、子章节起草 整合与优化、评估与迭代 | ||
| 知识发现 | VirSci[79] | RAG、多任务学习 模型微调、GraphRAG | 主题讨论、新颖性评估、摘要生成 知识库构建、多智能体协作 | |
| 星火科研助手[6] | 预训练、有监督微调 基于人类反馈的强化学习 | 成果调研、综述生成、领域更新追踪 论文研读、多文档问答、研究方向推荐 |
3 科技文献数据挖掘赋能LLMs的应用场景
3.1 支撑构建垂直大模型
3.2 支撑开发面向AI4S的高质量数据集
3.3 支持AI驱动的科学发现
表3 科技文献数据挖掘赋能LLMs的应用场景Table 3 Application scenarios of using large language models for data mining in scientific literature |
| 类型 | 场景 | 核心技术 | 典型案例 |
|---|---|---|---|
| 支撑构建通用大模型与垂直大模型 | 通用大模型 | 自监督学习、指令微调、迁移学习、RAG、基于人类反馈的强化学习、领域知识注入、提示工程 | PubScholar[108]集成科技资源、ORKG[93]结构化描述科技文献 |
| 垂直领域大模型 | 星火科研助手[6]、Web of Science研究助手、材料科学文本挖掘和信息抽取的语言模型MatSciBERT[21]、医疗诊断模型HuaTuo[88]、面向海洋科学的大语言模型OceanGPT[89]、脑科学关联知识图谱[91]、公共生命科学数据语义整合知识库Euretos[92] | ||
| 支撑开发高质量数据集 | AI4S科技文献数据库 | 主动学习、RAG、提示工程 多智能体协作、领域知识注入 | 酶化学关系抽取数据集EnzChemRED[96]、催化科学数据集Catalysis Hub[100]、材料科学数据集LLM4Mat-Bench[99] |
| 支持AI驱动科学发现 | 假设生成 | 上下文学习、思维链提示 基于文献的发现、人机协作 | 科技文献知识驱动的AI引擎SciAIEngine[78]、预测和生成金属有机框架的人工智能系统ChatMOF[82] |
| 实验验证 | 人工智能材料科学家MatPilot[112] | ||
| 决策支持 | 公共生命科学数据语义整合知识库Euretos[92] |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}