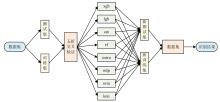
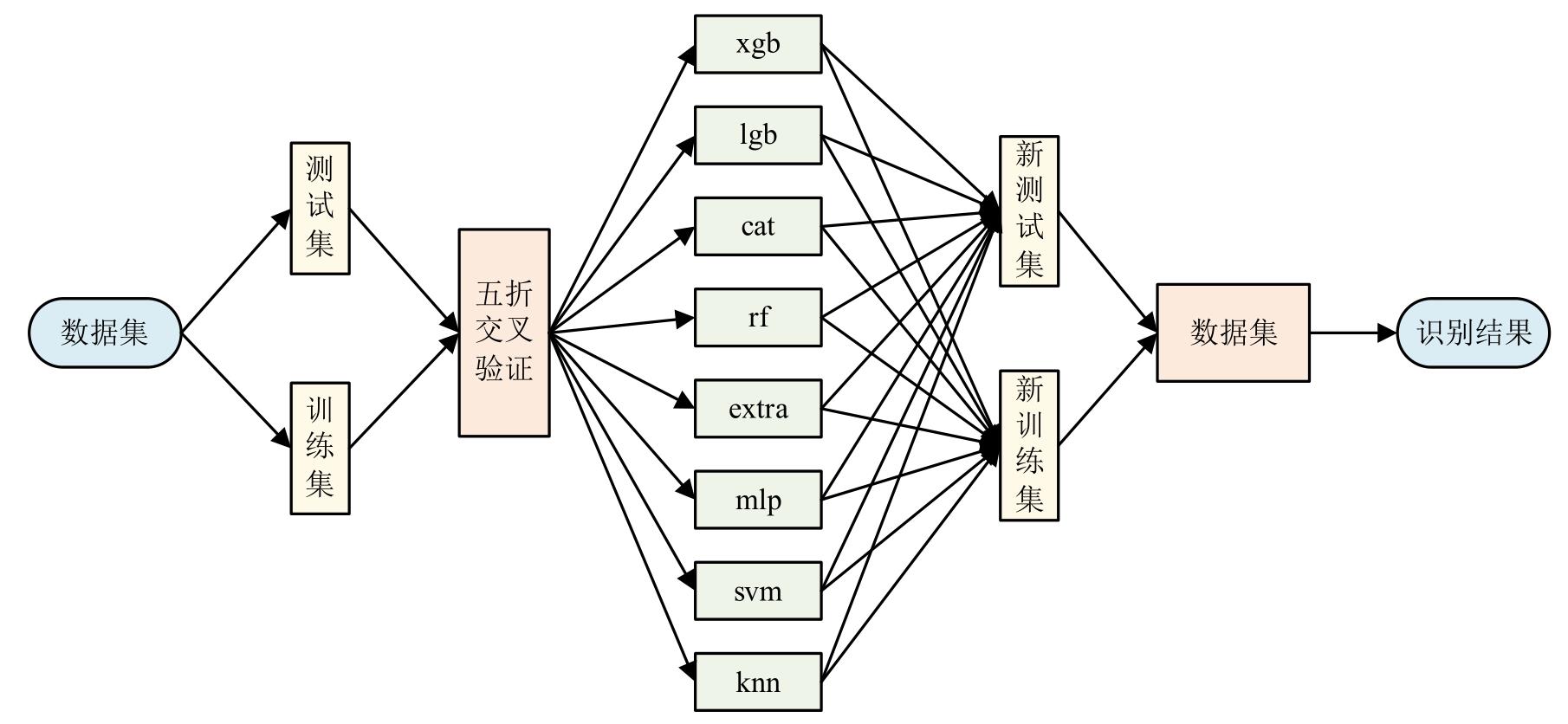
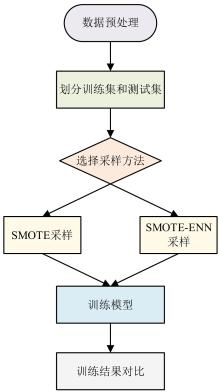
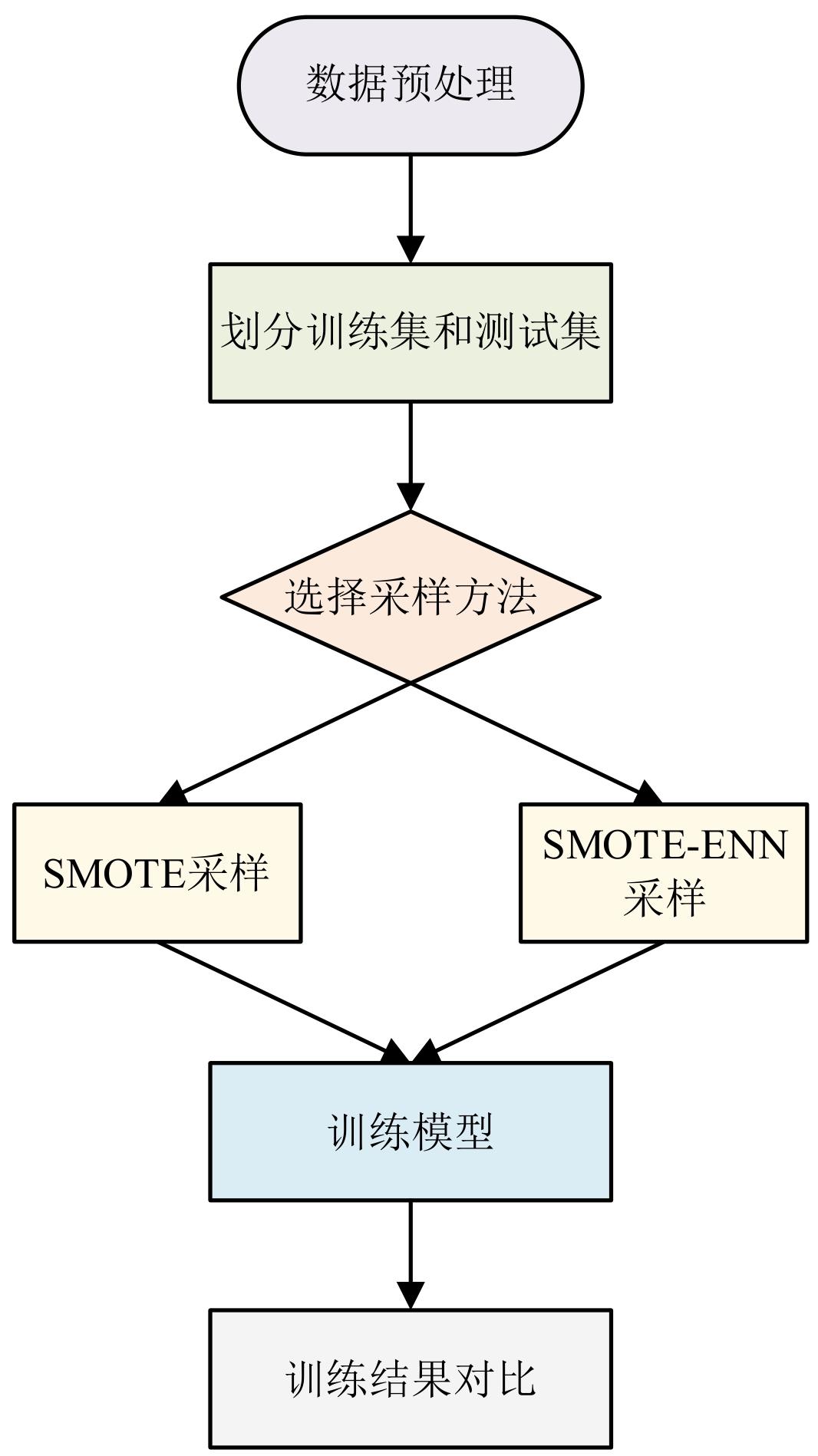
Journal of library and information science in agriculture ›› 2026, Vol. 38 ›› Issue (6): 86-97.doi: 10.13998/j.cnki.issn1002-1248.25-0536
Previous Articles Next Articles
CHEN Yuanyuan1, HU Shaohuang2, CHEN Xiaohong1
CLC Number:
| [1] |
|
| [2] |
中国科学院颠覆性技术创新研究组. 颠覆性技术创新研究-生命科学领域[M]. 北京: 科学出版社, 2020.
|
| [3] |
|
| [4] |
白光祖, 郑玉荣, 吴新年, 等. 基于文献知识关联的颠覆性技术预见方法研究与实证[J]. 情报杂志, 2017, 36(9): 38-44.
|
|
|
|
| [5] |
王知津, 周鹏, 韩正彪. 基于情景分析法的技术预测研究[J]. 图书情报知识, 2013, 30(5): 115-122.
|
|
|
|
| [6] |
曹悦, 白晨, 张英杰, 等. 颠覆性技术识别模型研究——以工业机器人领域为例[J]. 中国科技资源导刊, 2022, 54(2): 81-92.
|
|
|
|
| [7] |
陈育新, 卢俊, 韩毅. 基于专利文献的颠覆性技术识别研究——以人工智能为例[J]. 情报学报, 2022, 41(11): 1124-1133.
|
|
|
|
| [8] |
刘雨农, 石静, 梁琴琴. 基于STM的颠覆性技术主题识别研究[J]. 情报工程, 2023, 9(3): 81-91.
|
|
|
|
| [9] |
赵一鸣, 刘顺生, 吕璐成. 基于集成学习的颠覆性技术早期识别研究——以量子计算领域为例[J]. 数据分析与知识发现, 2025, 9(10): 85-98.
|
|
|
|
| [10] |
王莉晓, 陈伟, 邱含琪. 基于机器学习的颠覆性技术弱信号识别模型研究[J]. 数据分析与知识发现, 2024, 8(8): 63-75.
|
|
|
|
| [11] |
徐硕, 李静鸿, 安欣. 基于专利术语的颠覆性技术识别及实证研究[J]. 图书情报工作, 2024, 68(2): 62-72.
|
|
|
|
| [12] |
唐虎林, 苏成, 李旺雨. 基于系统思维的颠覆性技术弱信号分析理论研究[J]. 情报学报, 2025, 44(4): 398-413.
|
|
|
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
王燕鹏, 王学昭. 技术突破和场景牵引视角下颠覆性技术量化识别方法研究[J]. 情报理论与实践, 2025, 48(3): 143-150, 159.
|
|
|
|
| [17] |
李乾瑞, 郭俊芳, 黄颖, 等. 基于突变-融合视角的颠覆性技术主题演化研究[J]. 科学学研究, 2021, 39(12): 2129-2139.
|
|
|
|
| [18] |
冯立杰, 秦浩, 王金凤, 等. 融合专利数据与社交媒体数据的潜在颠覆性技术识别——基于深度学习模型[J]. 情报学报, 2024, 43(2): 181-197.
|
|
|
|
| [19] |
|
| [20] |
夏若雨. 基于多源数据的颠覆性技术识别方法研究[D]. 绵阳: 西南科技大学, 2024.
|
|
|
|
| [21] |
王海军, 于佳文. 基于专利和微博的颠覆性技术主题识别研究——以人工智能领域为例[J]. 中国科技论坛, 2024(7): 83-94, 109.
|
|
|
|
| [22] |
|
| [23] |
|
| [24] |
马晓迪. 基于机器学习的潜在颠覆性技术识别方法研究[D]. 北京: 北京工业大学, 2023.
|
|
|
|
| [25] |
|
| [26] |
|
| [27] |
范明姐. 基于多源异构数据的颠覆性技术早期识别研究[D]. 北京: 北京工业大学, 2020.
|
|
|
|
| [28] |
王萌萌, 吴艾晗, 邓琨升, 等. 基于学科交叉驱动的颠覆性技术预测研究[J]. 情报杂志, 2025, 44(3): 72-80, 138.
|
|
|
|
| [29] |
马亚雪, 王嘉杰, 巴志超, 等. 颠覆性技术的后向科学引文知识特征识别研究——以基因工程领域为例[J]. 图书情报工作, 2024, 68(1): 116-126.
|
|
|
|
| [30] |
|
| [31] |
|
| [32] |
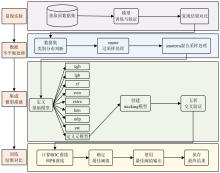
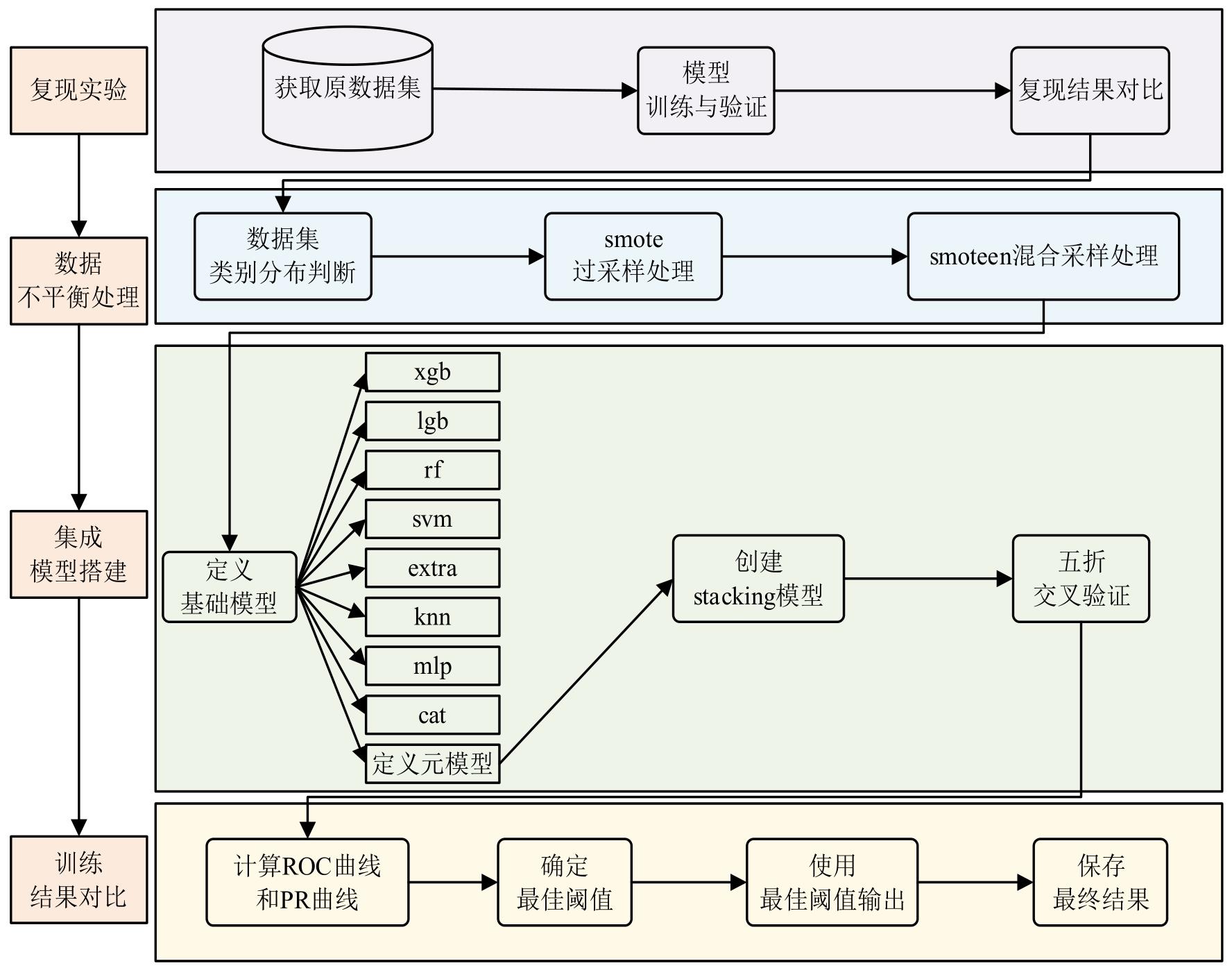
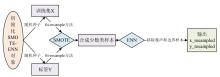
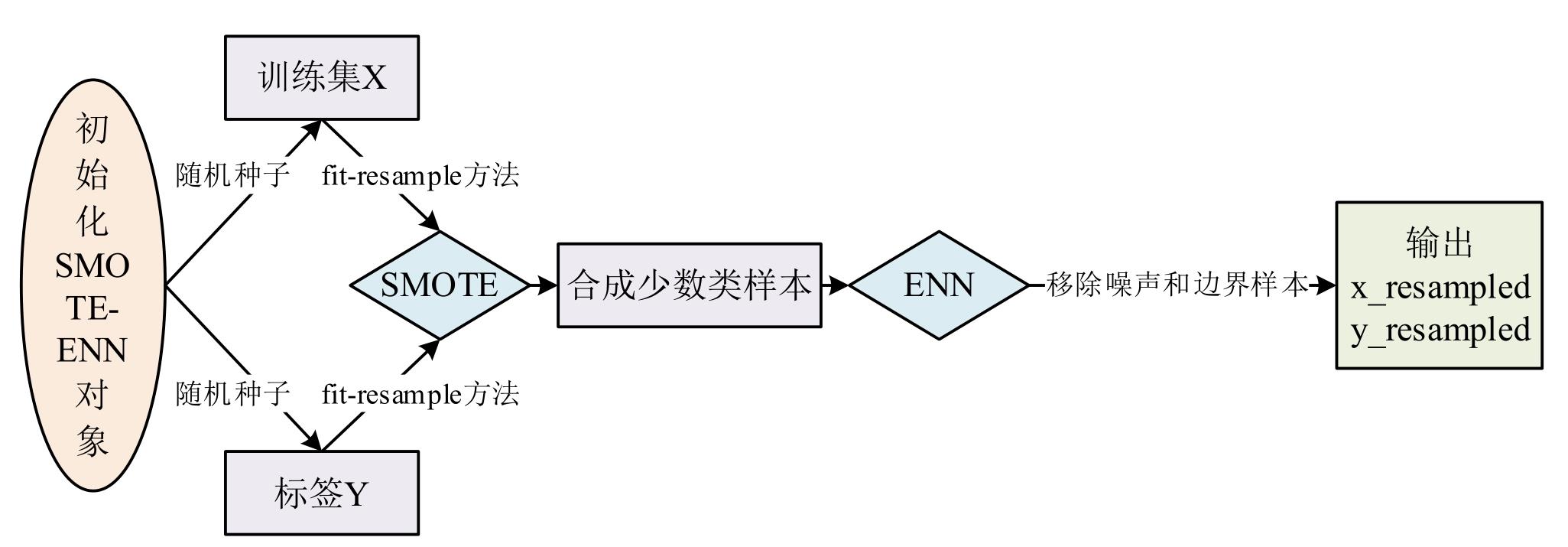
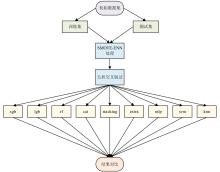
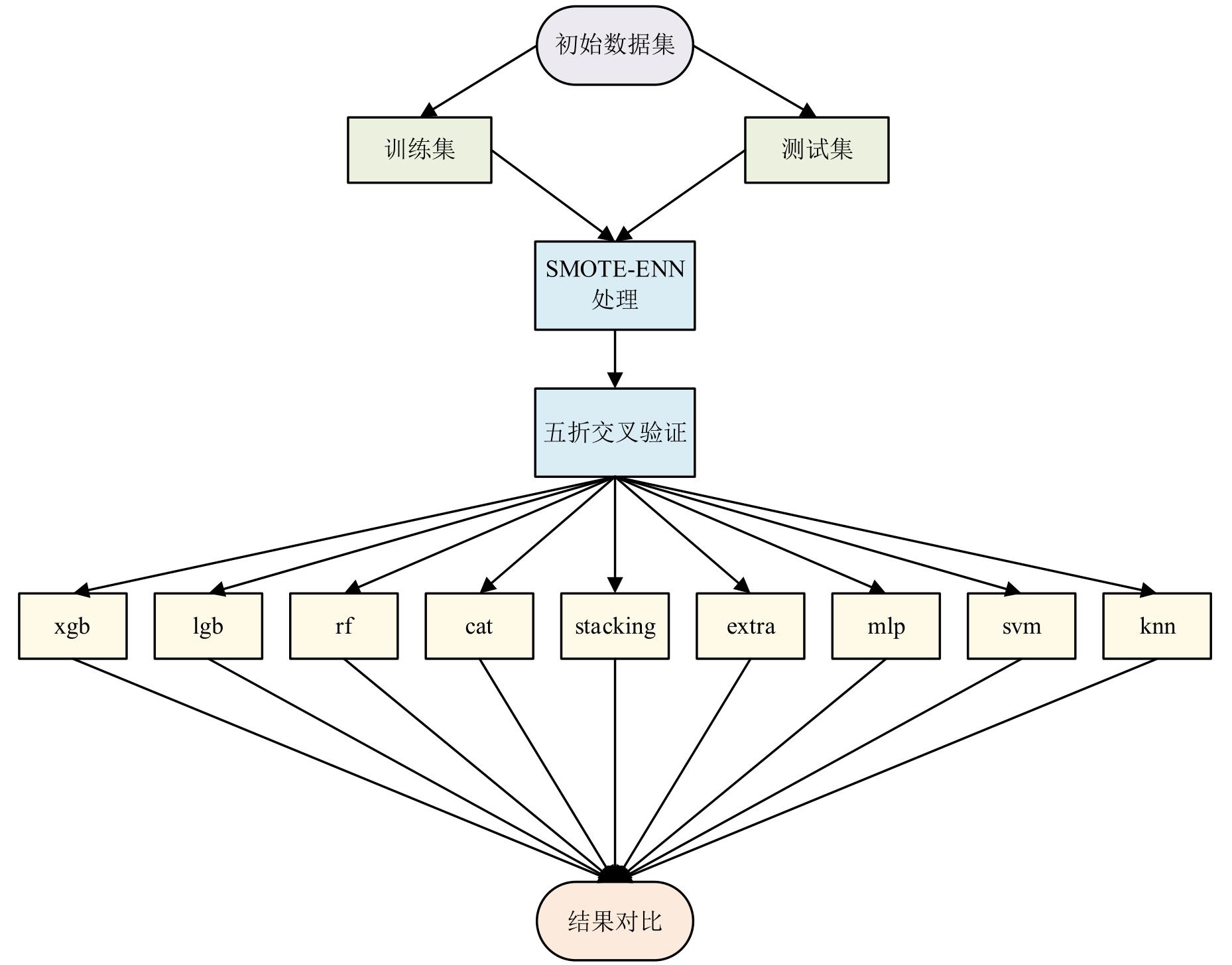
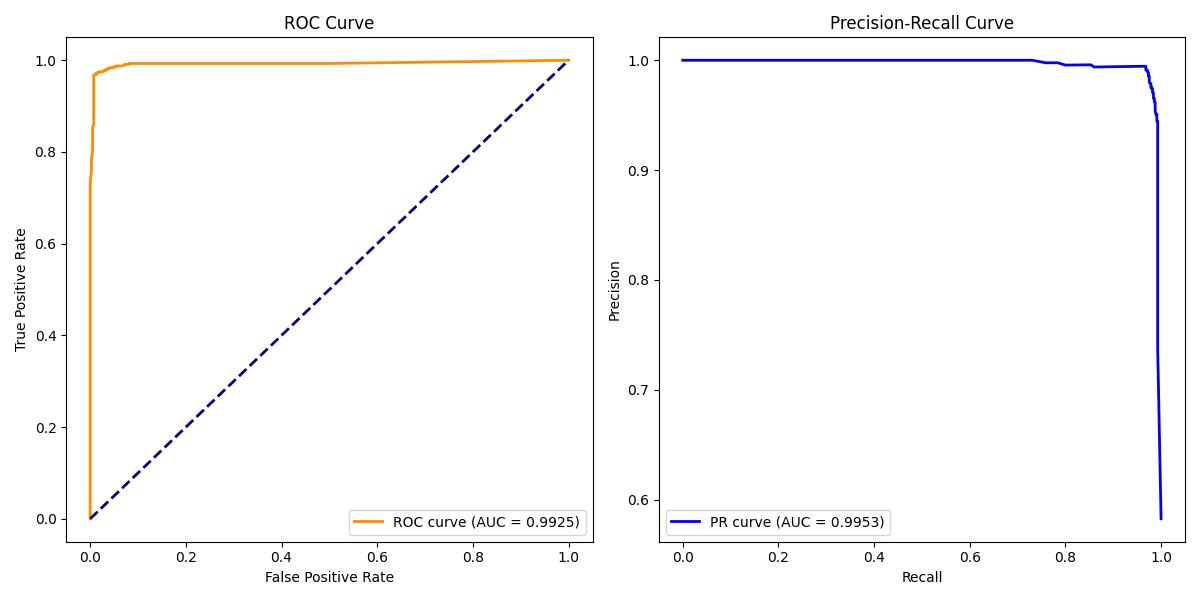
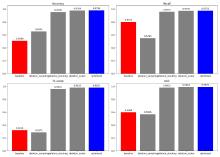
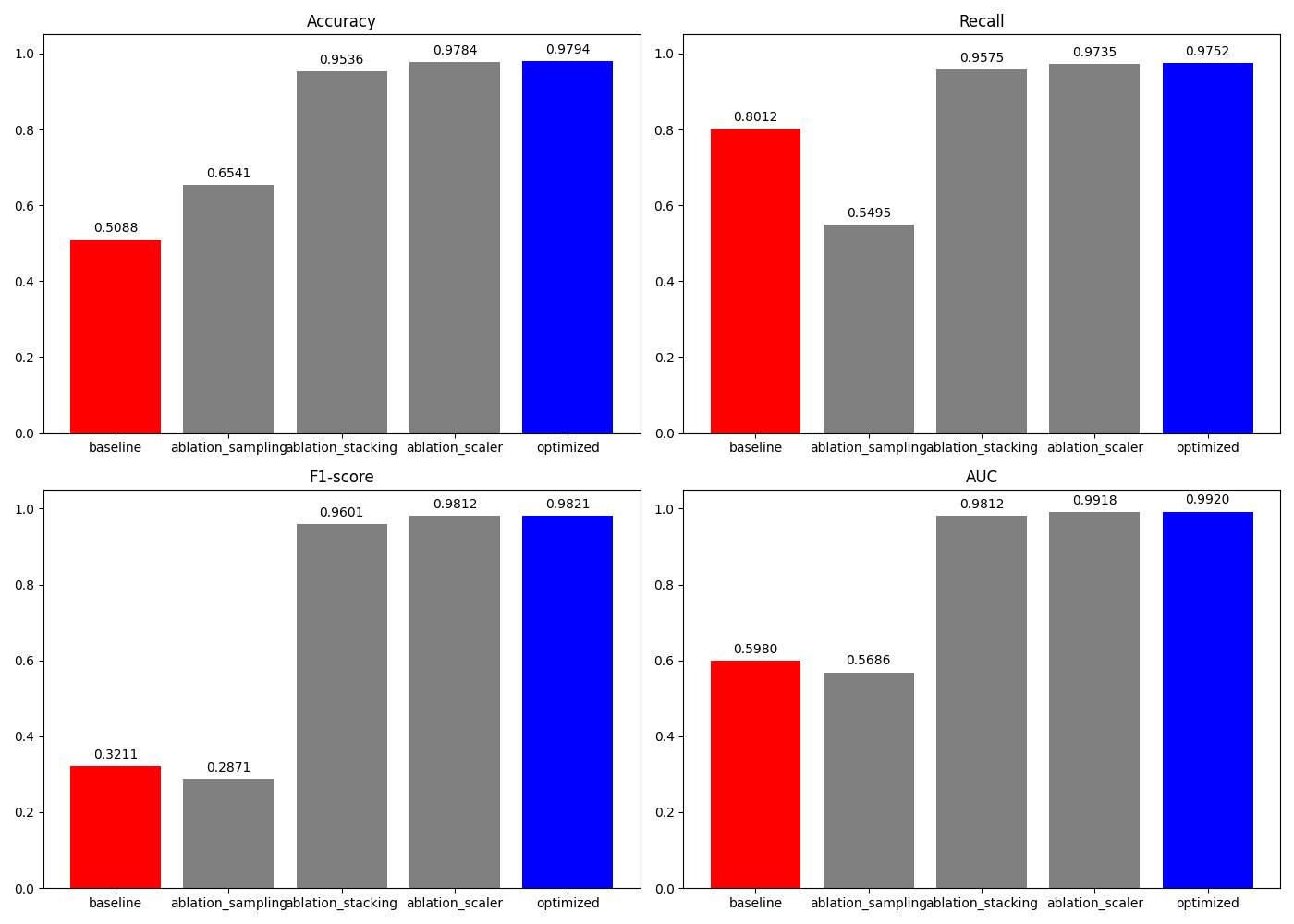
张高源, 赵瑞青, 张岩波, 等. 基于SMOTE-ENN结合改进动态集成选择算法构建DLBCL患者2年内复发预测模型[J]. 中国卫生统计, 2025, 42(1): 50-55, 61.
|
|
|
|
| [33] |
|
| [34] |
|
| [35] |
|
| [1] | WEI Tianyu, LIU Zhongyi, ZHANG Ning. Influencing Mechanism of the Social Role of Government Digital Human on Public Adoption Behavior [J]. Journal of library and information science in agriculture, 2025, 37(2): 49-60. |
| [2] | XIANG Rui, SUN Wei. Methodology for Assessing the Influence of Technical Topics Based on PhraseLDA-SNA and Machine Learning [J]. Journal of library and information science in agriculture, 2024, 36(4): 45-62. |
| [3] | ZHAO Wanjing, LIU Minjuan, LIU Hongbing, WANG Xin, DUAN Feihu. A Fine-grained Extraction Method of Chapter Structure of Documents Based on PDF Layout Features [J]. Journal of library and information science in agriculture, 2021, 33(9): 93-103. |
| [4] | HU Lin, LIU Tingting, LI Huan, CUI Yunpeng. Prospects for Machine Learning Research and its Application in Agriculture [J]. Journal of library and information science in agriculture, 2019, 31(10): 12-22. |
| [5] | ZHI Yingying. Exploration on the Application of Machine Learning in Library Discover System —Taking the Discover Tool Yewno Based on Knowledge Graph as Example [J]. Journal of library and information science in agriculture, 2018, 30(7): 47-50. |
|
||