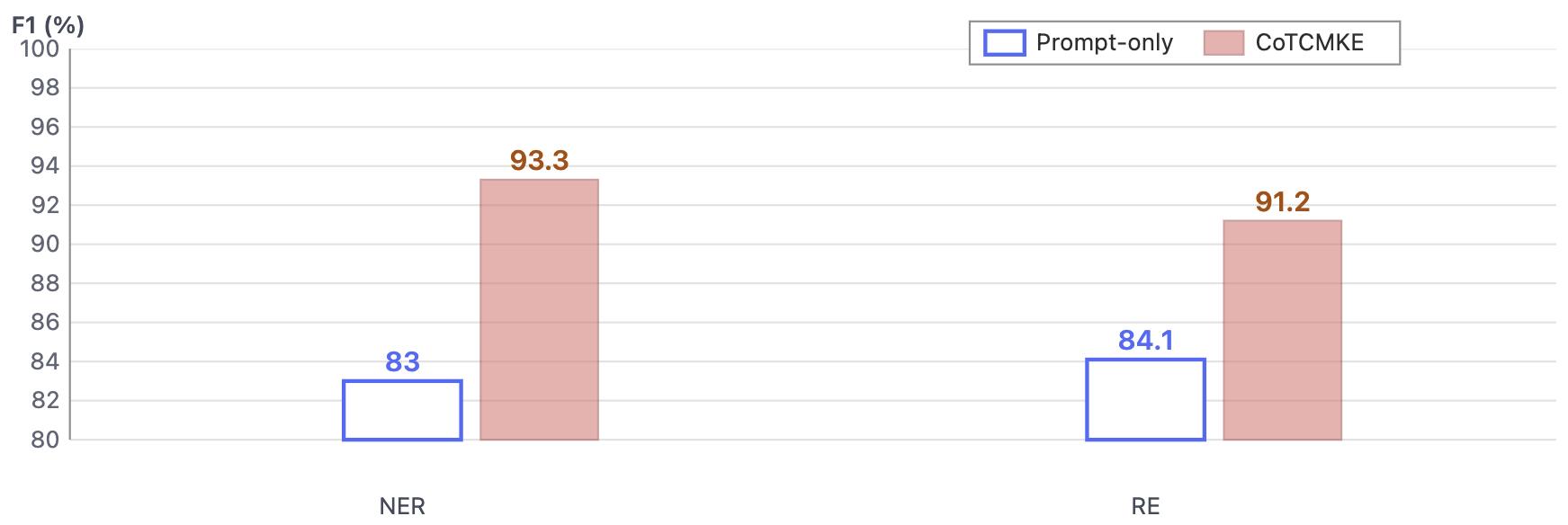
| [1] |
陈力. 数字人文视域下的古籍数字化与古典知识库建设问题[J]. 中国图书馆学报, 2022, 48(2): 36-46.
|
|
CHEN L. Digitalization of ancient books and construction of classical knowledge repository from the perspective of digital humanities[J]. Journal of library science in China, 2022, 48(2): 36-46.
|
| [2] |
邹苏, 张宗明. 习近平关于中医药的重要论述的核心要义、坚实根基及价值意蕴[J/OL]. 中国医学伦理学, 2024: 1-8.
|
|
ZOU S, ZHANG Z M. Xi Jinping's Important Discourse on Traditional Chinese Medicine has a profound value implication, as well as core principles and solid foundations[J/OL]. Chinese medical ethics, 2024: 1-8.
|
| [3] |
张伯礼. 新时代中医药传承发展的机遇与挑战[J]. 中国药理学与毒理学杂志, 2019, 33(9): 641-642.
|
|
ZHANG B L. Opportunities and challenges of traditional Chinese medicine inheritance and development in the new era[J]. Chinese journal of pharmacology and toxicology, 2019, 33(9): 641-642.
|
| [4] |
苏尤丽, 胡宣宇, 马世杰, 等. 人工智能在中医诊疗领域的研究综述[J]. 计算机工程与应用, 2024, 60(16): 1-18.
|
|
SU Y L, HU X Y, MA S J, et al. Review of research on artificial intelligence in traditional Chinese medicine diagnosis and treatment[J]. Computer engineering and applications, 2024, 60(16): 1-18.
|
| [5] |
JI S X, PAN S R, CAMBRIA E, et al. A survey on knowledge graphs: Representation, acquisition, and applications[J]. IEEE transactions on neural networks and learning systems, 2022, 33(2): 494-514.
|
| [6] |
车万翔, 窦志成, 冯岩松, 等. 大模型时代的自然语言处理: 挑战、机遇与发展[J]. 中国科学: 信息科学, 2023, 53(9): 1645-1687.
|
|
CHE W X, DOU Z C, FENG Y S, et al. Towards a comprehensive understanding of the impact of large language models on natural language processing: Challenges, opportunities and future directions[J]. Scientia sinica (informationis), 2023, 53(9): 1645-1687.
|
| [7] |
YIN S K, FU C Y, ZHAO S R, et al. A survey on multimodal large language models[J/OL]. arXiv preprint arXiv:2306.13549, 2023.
|
| [8] |
LIANG Q, LIU Y J, ZHOU W X, et al. Expanding the boundaries of vision prior knowledge in multi-modal large language models[J/OL]. arXiv: 2503.18034, 2025.
|
| [9] |
张伯礼, 张俊华. 中医药现代化研究20年回顾与展望[J]. 中国中药杂志, 2015, 40(17): 3331-3334.
|
|
ZHANG B L, ZHANG J H. Twenty years' review and prospect of modernization research on traditional Chinese medicine[J]. China journal of Chinese materia Medica, 2015, 40(17): 3331-3334.
|
| [10] |
王东波, 刘畅, 朱子赫, 等. SikuBERT与SikuRoBERTa: 面向数字人文的《四库全书》预训练模型构建及应用研究[J]. 图书馆论坛, 2022, 42(6): 31-43.
|
|
WANG D B, LIU C, ZHU Z H, et al. Construction and application of pre-trained models of siku Quanshu in orientation to digital humanities[J]. Library tribune, 2022, 42(6): 31-43.
|
| [11] |
童攀, 龙炳鑫, 拥措. 基于注意力机制藏文乌金体古籍文字识别研究[J]. 计算机技术与发展, 2023, 33(10): 163-168, 208.
|
|
TONG P, LONG B X, YONGCUO. Research on Tibetan Ujin ancient book character recognition based on attention mechanism[J]. Computer technology and development, 2023, 33(10): 163-168, 208.
|
| [12] |
文玉锋, 林伟杰, 夏翠娟, 等. 面向古籍文献智能处理的大语言模型效能测评[J]. 图书馆论坛, 2025, 45(8): 52-60.
|
|
WEN Y F, LIN W J, XIA C J, et al. Large language models for intelligent processing of ancient texts: A performance evaluation[J]. Library tribune, 2025, 45(8): 52-60.
|
| [13] |
刘洋, 王东波. 古籍智能信息处理研究现状[J]. 图书情报工作, 2024, 68(23): 120-138.
|
|
LIU Y, WANG D B. Current research on intelligent information processing for ancient books[J]. Library and information service, 2024, 68(23): 120-138.
|
| [14] |
王惠茹, 李秀红, 李哲, 等. 多模态预训练模型综述[J]. 计算机应用, 2023, 43(4): 991-1004.
|
|
WANG H R, LI X H, LI Z, et al. Survey of multimodal pre-training models[J]. Journal of computer applications, 2023, 43(4): 991-1004.
|
| [15] |
陈晋音, 席昌坤, 郑海斌, 等. 多模态大语言模型的安全性研究综述[J]. 计算机科学, 2025, 52(7): 315-341.
|
|
CHEN J Y, XI C K, ZHENG H B, et al. Survey of security research on multimodal large language models[J]. Computer science, 2025, 52(7): 315-341.
|
| [16] |
马咏梅, 耿生玲, 赵维纳, 等. 基于LoRA微调的撒拉族建筑知识图谱构建[J/OL]. 山西大学学报(自然科学版), 2025: 1-12.
|
|
MA Y M, GENG S L, ZHAO W N, et al. Construction of knowledge graph for salar architecture based on LoRA fine-tuning[J/OL]. Journal of Shanxi university (natural science edition), 2025: 1-12.
|
| [17] |
LI Q, SUN H X, XIAO F, et al. PS-CoT-Adapter: Adapting plan-and-solve chain-of-thought for ScienceQA[J]. Science China information sciences, 2024, 68(1): 119101.
|
| [18] |
WEI J, WANG X Z, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. 28 November 2022, New Orleans, LA, USA. ACM, 2022: 24824-24837.
|
| [19] |
WANG X, WEI J, SCHUURMANS D, ET AL. Self-consistency improves chain of thought reasoning in language models[J/OL]. arXiv preprint arXiv:2203.11171, 2022.
|
| [20] |
ZHOU D, SCHÄRLI N, HOU L, et al. Least-to-most prompting enables complex reasoning in large language models[J/OL]. arXiv: 2205.10625, 2022.
|
| [21] |
MA X L, LI J, ZHANG M. Chain of thought with explicit evidence reasoning for few-shot relation extraction[J/OL]. arXiv: 2311.05922, 2023.
|
| [22] |
KWAK A, MORRISON C, BAMBAUER D, et al. Classify first, and then extract: Prompt chaining technique for information extraction[C]//Proceedings of the Natural Legal Language Processing Workshop 2024. Miami, FL, USA. Stroudsburg, PA, USA: ACL, 2024: 303-317.
|
| [23] |
LI M C, ZHOU H X, YANG H, et al. RT: A Retrieving and Chain-of-Thought framework for few-shot medical named entity recognition[J]. Journal of the American medical informatics association, 2024, 31(9): 1929-1938.
|
| [24] |
LIU Y, WANG Z, ZHANG H, et al. ERA-CoT: Improving chain-of-thought through entity-relationship-aware reasoning for NER[C]. Thailand: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics Bangkok, 2024: 8780-8794.
|
| [25] |
CHEN F, FENG Y J. Chain-of-thought prompt distillation for multimodal named entity recognition and multimodal relation extraction[J/OL]. arXiv: 2306.14122, 2023.
|
| [26] |
TIAN H Y, YANG K, DONG X, et al. TCMLLM-PR: Evaluation of large language models for prescription recommendation in traditional Chinese medicine[J]. Digital Chinese medicine, 2024, 7(4): 343-355.
|
| [27] |
ZENG A H, XU B, WANG B W, et al. ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools[J/OL]. arXiv: 2406.12793, 2024.
|
| [28] |
叶淋潮, 邵会会, 谢振平. 基于精调LLaMA模型的中西医概念关系对比分析方法[J]. 中文信息学报, 2025, 39(2): 162-170.
|
|
YE L C, SHAO H H, XIE Z P. A contrastive study on the concept relations between traditional Chinese medicine and western medicine via finetuned LLaMA[J]. Journal of Chinese information processing, 2025, 39(2): 162-170.
|