


AI模型元数据规范发展现状与构建研究
|
姜恩波,正高级工程师,中国科学院成都文献情报中心知识系统部,副主任,研究方向为数字图书馆平台建设 |
|
秦瑜,硕士研究生,中国科学院成都文献情报中心,研究方向为智慧数据与智慧图书馆 |
收稿日期: 2025-06-22
网络出版日期: 2025-10-29
基金资助
中国科学院文献情报能力建设专项“科技态势感知与分析能力建设”
Development and Construction of Metadata Specifications for AI Models
Received date: 2025-06-22
Online published: 2025-10-29
【目的/意义】 本研究旨在回应当前人工智能模型不透明性、难以解释、可追溯性差等问题,提出建立统一的AI模型元数据规范,以提升模型的可发现性、透明度、互操作性和可重用性,进而推动可信任AI的发展。 【方法/过程】 文章以元数据质量评估理论和生命周期理论为基础,采用文献调研法、比较分析、问卷调查等方法,系统梳理和分析国内外已有的AI模型元数据实践,深入调查用户对元数据的认知与需求,并提出面向全生命周期的元数据构建方案。 【结果/结论】 用户认为AI模型元数据规范重要但对现有规范并不了解。现有AI模型元数据规范在元素命名、组织架构、内容细粒度解释等方面存在明显短板,影响模型信息的共享与复用。为此,文章提出了一个元数据框架,涵盖模型、数据、算法、技术特征、性能评估、风险与伦理、法律信息、相关资源等核心实体,并描述其间语义关系。研究认为,建立统一的AI模型元数据框架不仅有助于模型的信息化管理和平台互联互通,也将成为连接技术、伦理与治理的重要基础设施。未来,随着规范体系的不断完善与行业采纳,AI模型将更具可控性与可信赖性,推动技术生态的规范发展与跨界融合。
姜恩波 , 秦瑜 . AI模型元数据规范发展现状与构建研究[J]. 农业图书情报学报, 2025 : 1 -18 . DOI: 10.13998/j.cnki.issn1002-1248.25-0338
[Purpose/Significance As artificial intelligence (AI) systems are being widely deployed across diverse domains such as education, healthcare, and public governance, the absence of standardized metadata specifications has led to fragmented descriptions, inconsistent documentation, and difficulties in model evaluation and reuse. This study aims to address the pressing issues of opacity, lack of interpretability, and poor traceability in current AI models, which have increasingly become obstacles to the development of transparent and responsible AI. To overcome these challenges, this study proposes the establishment of a unified metadata specification for AI models to enhance their discoverability, transparency, interoperability, and reusability, thereby advancing the development of trustworthy AI and facilitating effective model governance. [Method/Process Grounded in metadata quality assessment theory and lifecycle theory, the study adopted a combination of research methods, including literature review, comparative analysis of existing specifications, and questionnaire surveys.We first conducted a systematic examination of domestic and international practices related to AI model metadata specifications to identify representative standards, frameworks, and implementation approaches. Through comparative analysis, the study investigated the structure, element organization, and semantic relationships of different specifications, highlighting their similarities, differences, and areas for improvement. Meanwhile, a targeted questionnaire survey was administered to researchers, developers, and practitioners to explore user awareness, perceptions, practical experiences, and specific needs regarding metadata specification and interoperability. Based on these findings, the study ultimately proposed a lifecycle-oriented framework for metadata specification construction, ensuring that it aligns with the key stages of AI model development, deployment, evaluation, and governance. [Results/Conclusions The findings reveal that, although users generally recognize the importance of metadata specifications for AI models, they are unaware of of the existing specifications. The current AI model metadata specifications have significant shortcomings in terms of element naming, structural organization, and descriptive granularity. These shortcomings hinder the effective sharing and reuse of model information. In response, the study proposed a comprehensive metadata framework encompassing key entities such as models, datasets, algorithms, technical features, performance evaluations, risks and ethics, legal information, and related resources, as well as the semantic relationships among these entities. The research concluded that establishing a unified metadata specification for AI models not only contributes to effective information management and cross-platform interoperability, but also serves as a critical infrastructure that links technology, ethics, and governance. As the metadata specification system matures and gains wider industry adoption, AI models will become increasingly controllable and trustworthy. This will promote a more regulated, collaborative, sustainable and integrated AI ecosystem.
Key words: AI models; model transparency; metadata specification; AI
表1 当前主流大语言模型公开发布的部分元数据信息Table 1 Publicly released metadata information of current mainstream large language models |
| 维度 | GPT-4[9] | BERT[10] | Claude[11] | LLaMA[12] | 文心一言 (ERNIE Bot)[13] |
|---|---|---|---|---|---|
| 所属公司 | OpenAI | Anthropic | Meta | 百度 | |
| 发布时间 | 2023.3 | 2018 | 2023 | 2023.2 | 2023.3 |
| 模型架构 | Transformer | Transformer | Transformer | Transformer | Transformer |
| 参数规模 | 未公开 | BERT-base:1.1亿 | 未公开 | LLaMA-1: 7B/13B/33B/65B LLaMA-2: 70B | 未公开 |
| 训练数据 | 仅声明互联网大规模文本、书籍等[14] | 英文维基百科、BookCorpus数据[15] | 仅声明使用互联网公开数据和第三方企业许可的数据[16] | The Pile、BooksCorpus、Common Crawl、C4(Colossal Clean Crawled Corpus)、arXiv等[17] | 仅声明覆盖中文互联网、维基百科、百度知识图谱、图片、语音等数据[18,19] |
| 训练方法 | 大规模预训练+RLHF等对齐技术,未公开具体的技术细节[13] | 自监督预训练-下游任务微调[15] | 自监督预训练 | 自监督预训练[17] | 自监督预训练-中文场景多任务微调[18] |
| 训练成本 | 未公开 | 未公开 | 未公开 | 未公开 | 未公开 |
| 版本和更新历史 | GPT-1(2018)、GPT-2(2019)、GPT-3(2020)、GPT-3.5(2022)、GPT-4(2023) | BERT-base、BERT-large同期发布 | Claude 1(2023年初) Claude 2(2023年中) | LLaMA-1(7B~65B,2023.2) LLaMA-2(70B,2023.7) | 文心一言(2023年3月首发)、随后迭代多个版本 |
| 道德与隐私声明 | “使用政策”“道德守则”以及隐私政策[7,22] | 应遵循通用的Google AI道德准则[23] | 强调用户数据保护与安全,对敏感请求设限[24,25] | 未发布明确的道德与隐私声明 | 发布个人信息保护规则、智能体功能服务条款、用户协议等[26-28] |
表2 AI模型元数据规范的发展Table 2 Development of metadata specifications for AI models |
| 时间 | 组织 | 规范 | 适用模型类型 | 主要贡献与特点 | 涉及的实体关系 |
|---|---|---|---|---|---|
| 2018 | Model Card | 机器学习模型 | 提出了标准化的模型文档格式,记录机器学习模型的关键信息,推动模型透明度 | 训练关系、评估关系、产生关系 | |
| 2018 | W3C | ML Schema | 机器学习模型 | 提出用于描述机器学习模型的规范,促进不同平台与系统之间的互操作性 | 训练关系、评估关系 |
| 2019 | Hugging Face | Model Card | 深度学习模型、大语言模型 | 专注于NLP领域,强调模型的复用性和社区贡献,进一步推动模型透明度 | 训练关系、评估关系、衍生关系、开发关系、反馈关系、产生关系 |
| 2019 | IBM | AI Factsheet | 机器学习模型、深度学习模型 | 记录AI系统的性能、偏见、可靠性、安全性等关键指标,提高AI系统的透明度与可审计性 | 衍生关系 |
| 2020 | Amazon | AI Service Cards | 机器学习模型、深度学习模型 | 为云服务中的AI模型提供详细元数据描述,帮助用户更好地理解和使用AI服务 | 衍生关系、产生关系 |
| 2021 | OpenAI | System Card | 大语言模型 | 提供模型的详细信息,促进用户对模型的理解和信任 | 更新关系、训练关系、评估关系、产生关系 |
表3 模型卡描述元素Table 3 Model card description elements |
| 数据项 | 数据项(中文) | 描述内容 |
|---|---|---|
| Model Details | 模型详细信息 | 名称和版本、类型 开发团队和发布日期 框架与算法、参数、公平性约束等信息 获取更多信息的论文或其他资源 引文详细信息 许可证 向何处发送有关模型的问题或评论 |
| Intended Use | 预期用例 | 预期用途 预期用户 范围外的用例 |
| Factors | 因素 | 相关因素 评价因素 |
| Metrics | 指标 | 模型性能测量 决策阈值 变化方法 |
| Evaluation Data | 评估数据 | 数据集 动机 预处理 |
| Training Data | 训练数据 | 数据来源及统计特征 数据采样策略与分布 |
| Quantitative Analyses | 定量分析 | 根据评估指标提供评估模型的单一结果 根据评估指标提供评估模型的交叉结果 |
| Ethical Considerations | 道德考虑 | 模型开发中的道德考虑因素,向利益相关者提出道德挑战和解决方案 |
| Caveats and Recommendations | 注意事项与建议 | 潜在误用风险 用户操作建议 |
表4 AI模型元数据描述信息Table 4 Metadata description information for AI models |
| 元数据项 | Model Card (Google)[29] | ML Schema (W3C)[30] | AI Factsheet (IBM)[31] | AI Service Cards (Amazon)[32] | System Card (OpenAI)[33] | Model Card (Hugging Face)[34] | 覆盖情况 | |
|---|---|---|---|---|---|---|---|---|
| 模型基本信息 | 模型名称 | √ | √ | √ | √ | √ | √ | 6 |
| 模型版本 | √ | √ | √ | 3 | ||||
| 开发团队 | √ | √ | √ | √ | 4 | |||
| 发布时间 | √ | √ | 2 | |||||
| 模型架构 | √ | √ | √ | 3 | ||||
| 模型算法 | √ | √ | 2 | |||||
| 模型参数 | √ | √ | √ | 3 | ||||
| 任务类型 | √ | √ | √ | √ | 4 | |||
| 应用场景 | √ | √ | √ | 3 | ||||
| 训练数据 | 数据集名称 | √ | √ | √ | √ | √ | 5 | |
| 数据来源 | √ | √ | 2 | |||||
| 数据特征 | √ | √ | √ | √ | 4 | |||
| 处理策略 | √ | √ | √ | 3 | ||||
| 评估数据 | 数据集名称 | √ | √ | √ | √ | 4 | ||
| 数据特征 | √ | √ | 2 | |||||
| 处理策略 | √ | 1 | ||||||
| 评估指标 | √ | √ | √ | √ | √ | √ | 6 | |
| 技术特征 | 输入特征 | √ | √ | 2 | ||||
| 输出特征 | √ | √ | 2 | |||||
| 训练技术 | √ | 1 | ||||||
| 计算设施 | √ | √ | 2 | |||||
| 伦理与风险考虑 | 伦理与风险审查 | √ | √ | 2 | ||||
| 数据隐私 | √ | 1 | ||||||
| 偏见与公平性 | √ | √ | √ | 3 | ||||
| 安全性 | √ | √ | 2 | |||||
| 反馈途径 | √ | √ | √ | 3 | ||||
| 覆盖情况 | 50% | 53.8% | 57.7% | 30.8% | 42.3% | 53.8% | ||
表5 元数据字段差异示例Table 5 Examples of metadata field variations |
| 元数据字段 | Model Card (Google) | ML Schema (W3C) | AI Factsheet (IBM) | AI Service Cards (Amazon) | System Card (OpenAI) | Model Card (Hugging Face) |
|---|---|---|---|---|---|---|
| 模型基本信息 | Model Details | Model | Model Information | Overview | Introduction | Model Details |
| 应用场景 | Intended Use | Intended Domain | Intended use cases and limitations | Uses | ||
| 训练数据 | Training Data | Dataset | Training Data | Model Data & Training | Training Details | |
| 评估指标 | Metrics | Model Evaluation | Performance Metrics | Performance Expectations | Observed Safety Challenges and Evaluations | Evaluation |
| 偏见与公平性 | Bias | Fairness and Bias | Bias, Risks, and Limitations | |||
| 反馈途径 | Contact Information | Further Information | Model Card Contact |
表6 受访者个人特征分布Table 6 Distribution of respondents' personal characteristics |
| 个人特征 | 占比/% | |
|---|---|---|
| 年龄 | 18~25岁 | 19.51 |
| 26~35岁 | 65.85 | |
| 36~45岁 | 9.76 | |
| 46岁以上 | 4.88 | |
| 职业 | 学生 | 19.51 |
| 教师 | 19.51 | |
| 科研人员 | 26.83 | |
| 企业员工 | 34.15 | |
| 机构性质 | 高等院校 | 31.71 |
| 研究机构 | 29.27 | |
| 公司企业 | 36.59 | |
| 其他性质 | 2.44 | |
| 学历 | 本科及以下 | 12.20 |
| 硕士研究生 | 56.10 | |
| 博士研究生 | 31.71 | |
| 行业 | 金融 | 2.44 |
| 医疗 | 9.76 | |
| 教育 | 17.07 | |
| 电商 | 17.07 | |
| 信息与通信技术 | 46.34 | |
| 其他行业 | 7.32 | |
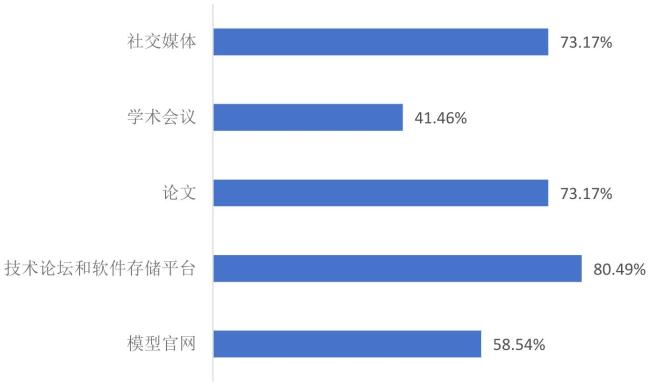
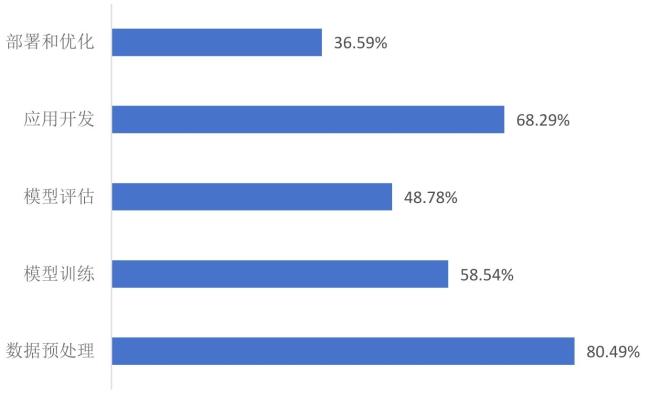
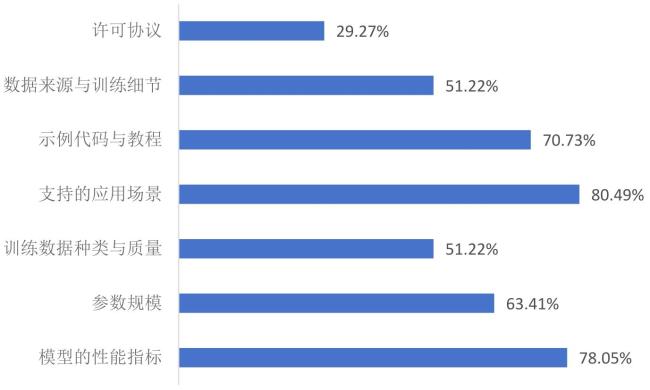
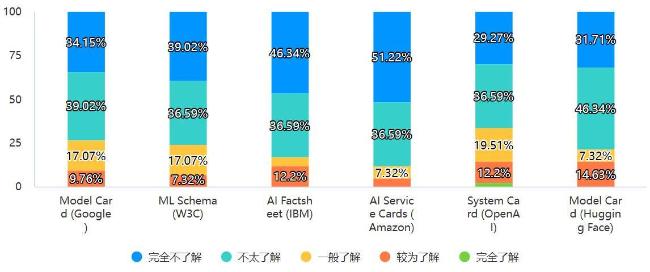
图5 受访者对6种规范了解情况柱状图Fig.5 Radar chart of respondents' familiarity with six specifications |
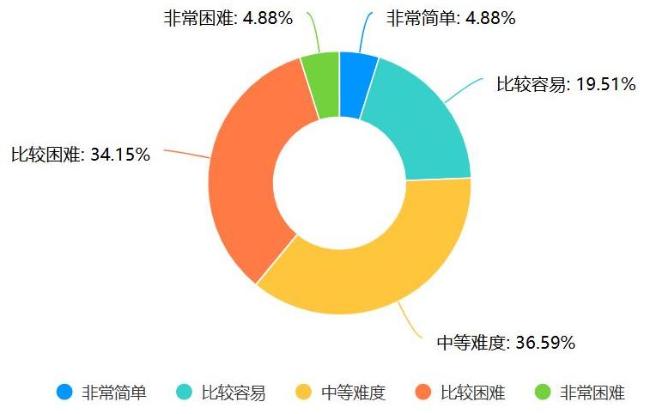
图6 受访者对AI模型使用门槛的认知情况统计Fig.6 Statistics on respondents' perception of barriers to using AI models |
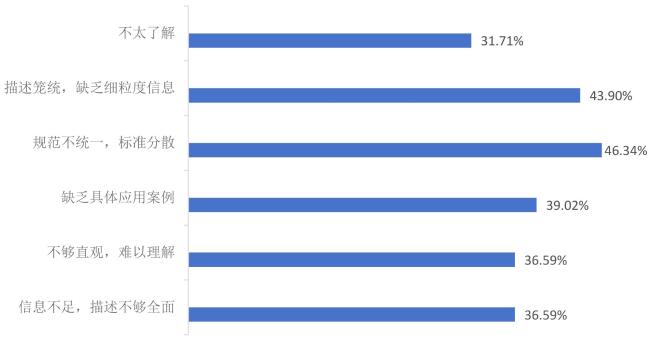
图7 受访者对现有AI模型元数据规范的不足性认知情况Fig.7 Respondents' perception of shortcomings in existing metadata specifications for AI models |
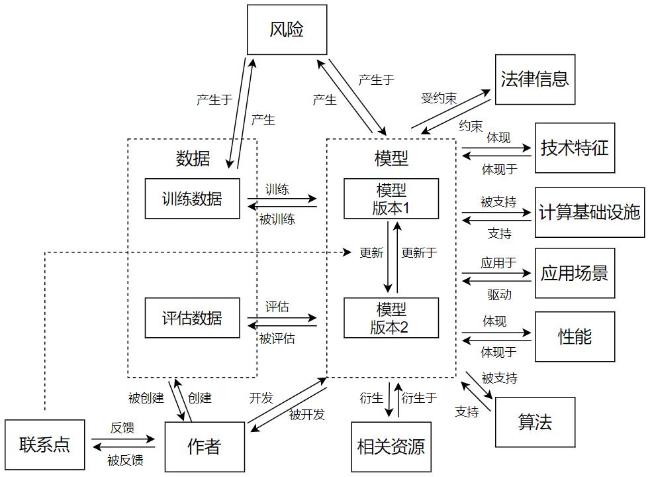
表7 模型实体分类Table 7 Model entity classification |
| 实体类别 | 描述内容 | 支撑字段举例 |
|---|---|---|
| 模型 | 标识信息、开发时间、模型类型、模型架构、模型参数等信息 | Model Description、Model type |
| 数据 | 模型涉及的数据集的来源、类型、格式及其数据处理、数据标注等信息 | Data、Training Data、Testing Data |
| 算法 | 算法名称与类型、算法原理、优化策略、超参数配置等信息 | Algorithm |
| 作者 | 模型的开发团队与数据集的创建者 | Authors |
| 基础设施 | 模型需要的开发环境、训练环境与部署环境等软硬件配置 | Compute Infrastructure |
| 技术特征 | 模型的技术属性、训练配置与优化技术等信息 | Technical Specifications |
| 性能 | 模型的各种评估/验证过程与结果、性能指标等 | Factors、Metrics、Performance Expectations |
| 应用场景 | 模型可适用的领域、场景以及实际应用案例 | Uses、Task、Intended Use Cases and Limitation |
| 风险 | 模型可能存在的数据隐私、社会伦理、模型偏见等法律与伦理风险,以及风险缓解措施等 | Bias, Risks, and Limitations |
| 法律信息 | 知识产权声明、许可协议、隐私信息、法律合规性与其他可能与法律相关的信息等 | License、Licensing Information、Privacy、Intellectual Property |
| 相关资源 | 其他与模型相关的论文及论文引用、文档与教程等链接 | More Information、Model Sources、Quick Link |
| 联系点 | 用于用户与开发者之间的反馈与交流,可服务于模型的更新与迭代,包括客户支持邮箱、社区论坛链接、问题反馈链接等联系性信息 | Contact |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
OpenAI. GPT-4 is OpenAI's most advanced system, producing safer and more useful responses[EB/OL]. [2025-03-02].
|
| [10] |
Google. BERT[EB/OL]. [2025-03-02].
|
| [11] |
Anthropic. Claude[EB/OL]. [2025-03-02].
|
| [12] |
Meta. Llama[EB/OL]. [2025-03-02].
|
| [13] |
百度. 文心一言(ERNIE Bot)[EB/OL]. [2025-03-02].
|
| [14] |
OPENAI,
|
| [15] |
|
| [16] |
你们如何在模型训练中使用个人数据?[EB/OL]. [2025-01-26].
|
| [17] |
|
| [18] |
|
| [19] |
百度AI模型“文心一言”新鲜体验[EB/OL]. [2025-01-26].
|
| [20] |
OpenAI. GPT-4[EB/OL]. [2025-01-26].
|
| [21] |
|
| [22] |
OpenAI. Privacy policy[EB/OL]. [2025-01-26].
|
| [23] |
Google. Our principles[EB/OL]. [2025-01-26].
|
| [24] |
Claude. Privacy policy[EB/OL]. [2025-01-26].
|
| [25] |
Claude. Privacy & legal[EB/OL]. [2025-01-26].
|
| [26] |
百度. 文心一言用户协议[EB/OL]. [2025-01-26].
|
| [27] |
百度. 文心一言个人信息保护规则[EB/OL]. [2025-01-26].
|
| [28] |
百度. 智能体功能服务条款[EB/OL]. [2025-01-26].
|
| [29] |
|
| [30] |
|
| [31] |
IBM. FactSheet examples overview[EB/OL]. [2025-01-26].
|
| [32] |
Amazon. Resources that promote AI transparency[EB/OL]. [2025-01-26].
|
| [33] |
OpenAI. OpenAI o1 system card[EB/OL]. [2025-01-26].
|
| [34] |
HuggingFace. huggingface_hub[EB/OL]. [2025-01-26].
|
| [35] |
|
| [36] |
黄莺, 李建阳. 元数据质量评估方法及模型研究[J]. 图书馆学研究, 2013(12): 52-56, 51.
|
| [37] |
程颖. 数字资源元数据质量管理的研究与探索[J]. 图书馆, 2015(7): 66-69, 104.
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
管珍珍. 信息生命周期视角下智慧情报赋能医药企业核心竞争力研究[D]. 哈尔滨: 黑龙江大学, 2024.
|
| [44] |
尹文武. 信息生命周期理论下的移动图书馆信息服务质量控制[J]. 图书馆理论与实践, 2017(4): 91-93.
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
郭海玲, 刘仲山. GDPR对我国跨境数字贸易企业个人数据保护研究: 基于数据生命周期理论[J]. 情报杂志, 2023, 42(10): 194-201.
|
| [49] |
马静. 数据生命周期视角下高校科学数据共享研究[D]. 哈尔滨: 黑龙江大学, 2024.
|
| [50] |
FAIR digital object framework documentation[EB/OL]. [2025-01-26].
|
| [51] |
AI智能大模型: 未来发展趋势人工智能AI大模型智能AI发展开发设计[EB/OL]. [2025-01-26].
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}