


DeepSeek赋能领域知识图谱低成本构建研究
|
史忠艳,硕士研究生,研究方向为知识图谱 |
|
雷洁,博士,助理研究员,研究方向为信息资源管理、知识组织 |
|
孙坦,博士,研究馆员(二级),研究方向为数字信息描述与组织 |
|
赵瑞雪,博士,研究员,研究方向为农业信息管理系统 |
|
李娇,博士,副研究员,研究方向为知识图谱与知识服务 |
|
黄永文,博士,研究员,研究方向为知识组织与知识服务 |
收稿日期: 2025-01-22
网络出版日期: 2025-05-30
基金资助
国家社会科学基金一般项目“多模态科技资源的语义组织与关联发现服务研究”(22BTQ079)
中国科协青年人才托举工程项目“面向科研论文的科学论证语义识别与解析研究”(2022QNRC001)
Research on DeepSeek-Empowered Low-Cost Construction of Domain-Specific Knowledge Graphs
Received date: 2025-01-22
Online published: 2025-05-30
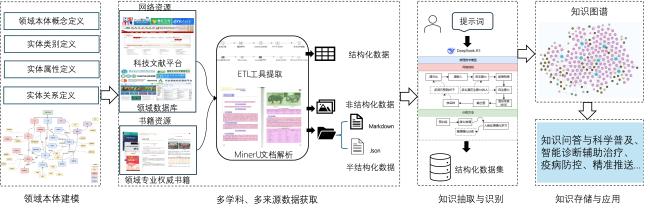
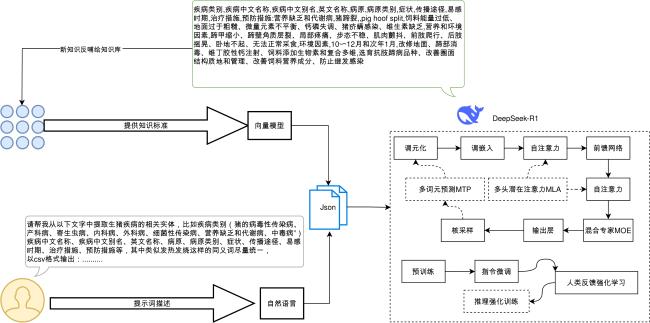
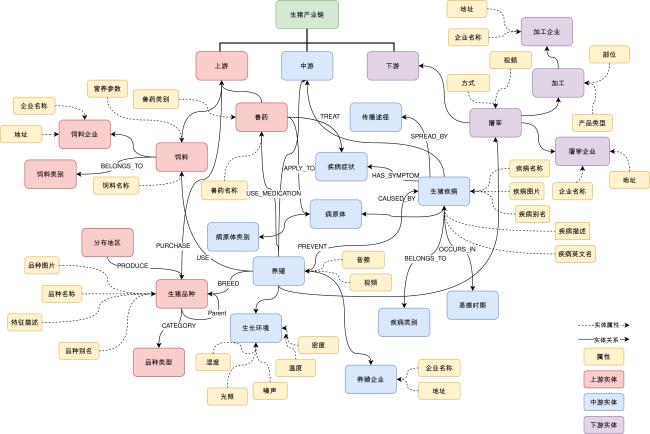
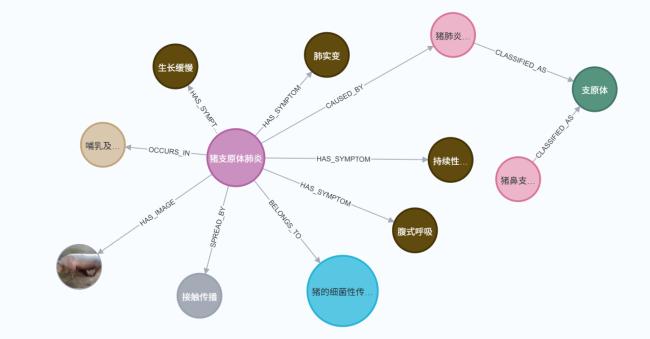
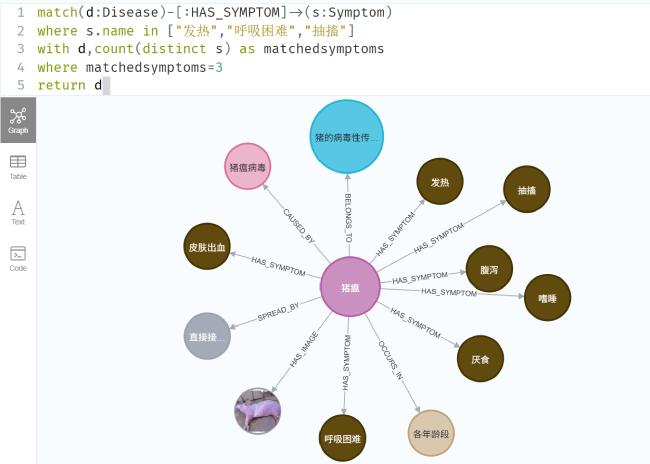
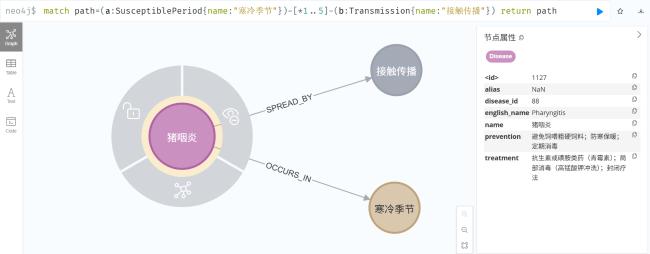
[目的/意义] 在以DeepSeek为代表的开源大语言模型驱动知识工程范式变革的背景下,本研究针对传统领域知识图谱构建中存在的专家规则依赖度高、人工标注成本大、多源数据处理效率低等瓶颈问题,提出基于DeepSeek的领域知识图谱低成本构建方法。 [方法/过程] 通过构建本体建模、数据融合、智能抽取的方法框架,基于领域认知特征设计本体模型,构建多源异构数据融合方法实现数据结构统一表征,创新性地将DeepSeek与知识抽取相结合,提出语义理解增强、提示工程的领域知识抽取技术体系。 [结果/结论] 以生猪全产业链领域知识图谱构建为实证对象,定义产业链结构、21类核心实体及其属性关系,实现面向智慧养殖的生猪产业知识建模。实验表明,DeepSeek-R1在零样本学习条件下,对生猪疫病防治场景的实体识别F1值达0.92。本研究为领域知识图谱构建提供了“机器初筛——人工精校”协同范式,验证了大语言模型在垂直领域的知识抽取潜力,对推动DeepSeek赋能知识图谱低成本构建具有研究价值与实践参考。
史忠艳 , 雷洁 , 孙坦 , 赵瑞雪 , 李娇 , 黄永文 , 鲜国建 . DeepSeek赋能领域知识图谱低成本构建研究[J]. 农业图书情报学报, 2025 : 1 -14 . DOI: 10.13998/j.cnki.issn1002-1248.25-0218
[Purpose/Significance] In recent years, large language models (LLMs) have achieved revolutionary breakthroughs in semantic understanding and generation capabilities through massive text pre-training. This has injected brand-new impetus into the field of knowledge engineering. As a structured knowledge carrier, the knowledge graph has unique advantages in integrating heterogeneous data from multiple sources and constructing an industrial knowledge system. In the context of a paradigm shift in the field of knowledge engineering driven by the emergence of open-source LLMs such as DeepSeek, this study proposes a cost-effective method for constructing domain knowledge graphs based on DeepSeek. We aim to address the limitations of traditional domain knowledge graphs, such as high dependence on expert rules, the high cost of manual annotation, and inefficient processing of multi-source data. [Methods/Processes] We proposed the semantic understanding-enhanced, cue-engineered domain knowledge extraction technology system, constructed on the methodological framework of manually constructing ontology modelling. In order to process the acquired data, the ETL\MinerU and other tools were used, and the DeepSeek-R1application programming interface was then invoked for intelligent extraction. The ontology model was designed based on domain cognitive features and the multi-source heterogeneous data fusion method was used to achieve the unified characterization of the data structure. Furthermore, the DeepSeek and knowledge extraction were combined. Our system provides a cost-effective reusable technical paradigm for constructing domain knowledge graphs, as well as efficient knowledge extraction, leveraging the advanced powerful textual reasoning ability of the DeepSeek model. [Results/Conclusions] In this study, we take the construction of a domain knowledge map of the entire pig industrial chain as an empirical object. We define the structure of the industrial chain, identify 21 types of core entities and describe their attribute relationships. We achieve the knowledge modelling of the pig industry with a focus on smart farming. The methodology developed in this research was also employed to process and extract knowledge from online and offline resource data. Preliminary experiments demonstrate that DeepSeek-R1 exhibits an F1 value of 0.92 when recognizing the attributes of 161 diseases and 11 types of entities in pig disease control scenarios under zero-sample learning conditions. These experiments also ascertain the reusability of the methodology for other links in the chain. Concurrently, the constructed knowledge map of the entire industrial chain of pigs will be utilized for the design and validation of intelligent application scenarios, with the objective of promoting the intelligent information processing in the pig industry. This study proposes a synergistic paradigm for constructing domain knowledge graphs using DeepSeek, a method that combines deep learning with manual calibration for efficient knowledge extraction and ensure accuracy. This approach ensures the efficiency of knowledge extraction and verifies the knowledge extraction potential of LLMs in vertical domains. The study's findings contribute to the extant literature and offer a practical reference for the promotion of DeepSeek-enabled cost-effective construction of knowledge graphs.
表1 提示词框架Table 1 Prompt frames |
| 框架 | 介绍 | 关键字段 |
|---|---|---|
| RTF框架 | 最简单的入门框架,适用于通用任务,快速问答、信息查询等 | 角色(ROLE):指定大模型角色,明确专业背景和承担角色 任务(TASK):定义具体任务或要解决的问题 格式(FORMAT):指定输出格式 |
| ROSES框架 | 将交互细分为5个核心部分,进行目的明确的交流,较RTF框架细化了其任务描述部分,适合需要明确角色和目标的交互,强调场景和解决方案,如咨询服务、问题解决等 | 角色(Role):指定大模型的角色 目标(Objective):描述要实现的目标或想要大模型完成的任务 场景(Scenario):提供与请求相关的背景信息或上下文 预期解决方案(Expected Solution):定义期望的结果 步骤(Steps):询问实现解决方案所需的具体步骤或操作 |
| SAGE框架 | 用于明确优化与人工智能模型的交互工程,适用于需要详细情况和行动的复杂任务 | 情况(Situation):描述任务执行的上下文或背景 行动(Action):明确需要进行的操作或步骤 目标(Goal):指出任务完成后应达到的目的或效果 预期 (Expectation):对输出结果的具体要求,包括格式、时间限制等 |
| CoT模式 | CoT模式称为思维链模式,让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能 | 指令(Instruction):用于描述问题并且告知大模型的输出格式 逻辑依据(Rationale):CoT的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识 示例(Exemplars):以少样本的方式为大模型提供输入输出对的基本格式 |
| CoD模式 | 由Salesforce、麻省理工学院和哥伦比亚大学的研究人员推出的一种提示方法,使用递归的方式来创建越来越好的输出提示,生成的文章摘要更加密集且适合理解。适用于总结性、长输出格式内容场景 | 指令(Instruction):明确大语言模型进行的任务和目的 步骤(Steps):设置执行任务步骤,并定义相关实体 指南(Guide):确定输出细节以及格式 |
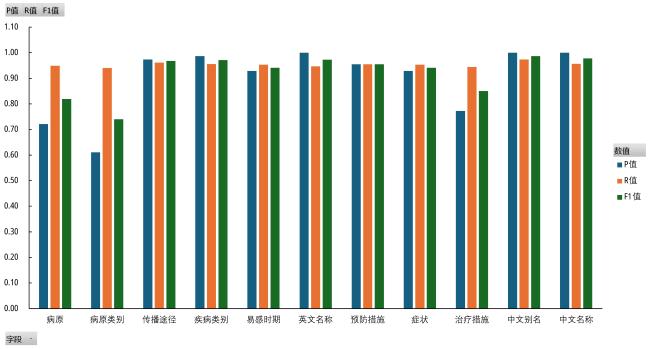
表2 各字段识别及抽取结果Table 2 Field-wise recognition and extraction results |
| 字段名称 | P | R | F1 |
|---|---|---|---|
| 疾病类别 | 0.99 | 0.96 | 0.97 |
| 中文名称 | 1.00 | 0.96 | 0.98 |
| 中文别名 | 1.00 | 0.97 | 0.99 |
| 英文名称 | 1.00 | 0.95 | 0.97 |
| 病原 | 0.72 | 0.95 | 0.82 |
| 病原类别 | 0.61 | 0.94 | 0.74 |
| 症状 | 0.93 | 0.95 | 0.94 |
| 传播途径 | 0.97 | 0.96 | 0.97 |
| 易感时期 | 0.93 | 0.95 | 0.94 |
| 治疗措施 | 0.77 | 0.94 | 0.85 |
| 预防措施 | 0.95 | 0.95 | 0.95 |
| 1 |
秦小林, 古徐, 李弟诚, 等. 大语言模型综述与展望[J]. 计算机应用, 2025, 45(3): 685-696.
|
| 2 |
王萌, 王昊奋, 李博涵, 等. 新一代知识图谱关键技术综述[J]. 计算机研究与发展, 2022, 59(9): 1947-1965.
|
| 3 |
徐增林, 盛泳潘, 贺丽荣, 等. 知识图谱技术综述[J]. 电子科技大学学报, 2016, 45(4): 589-606.
|
| 4 |
刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.
|
| 5 |
车万翔, 窦志成, 冯岩松, 等. 大模型时代的自然语言处理: 挑战、机遇与发展[J]. 中国科学: 信息科学, 2023, 53(9): 1645-1687.
|
| 6 |
|
| 7 |
李晓理, 刘春芳, 耿劭坤. 知识图谱与大语言模型协同共生模式及其教育应用综述[J/OL]. 计算机工程与应用, 2025: 1-15.
|
| 8 |
韩普, 陈文祺, 叶东宇. 面向中文电子病历的多模态知识图谱构建方法研究[J]. 图书情报工作, 2024, 68(23): 30-40.
|
| 9 |
毛瑞彬, 朱菁, 李爱文, 等. 基于自然语言处理的产业链知识图谱构建[J]. 情报学报, 2022, 41(3): 287-299.
|
| 10 |
姚奕, 陈朝阳, 杜晓明, 等. 多模态知识图谱构建技术及其在军事领域的应用综述[J]. 计算机工程与应用, 2024, 60(22): 18-37.
|
| 11 |
陈怡然, 熊竹青, 周脚根, 等. 畜禽养殖业数据应用展望和问题分析[J]. 中国科学院院刊, 2024, 39(11): 1982-1993.
|
| 12 |
刘烨宸, 李华昱. 领域知识图谱研究综述[J]. 计算机系统应用, 2020, 29(6): 1-12.
|
| 13 |
|
| 14 |
张才科, 李小龙, 郑胜, 等. 基于大语言模型的知识图谱构建及应用研究[J]. 计算机科学与探索, 2024, 18(10): 2656-2667.
|
| 15 |
|
| 16 |
周正达, 王昊, 汪琳, 等. ChatKG: 一种基于大语言模型和提示工程的非遗知识图谱构建框架: 以中国非遗陶瓷制作工艺为例[J/OL]. 图书馆杂志, 2025: 1-30.
|
| 17 |
陈宋生, 王明. 基于大语言模型的财会知识图谱构建及应用展望[J]. 会计之友, 2025(5): 152-161.
|
| 18 |
韦一金, 陈彦清, 王秀东, 等. 基于大语言模型的《中国小麦品种志》信息提取[J]. 数据与计算发展前沿(中英文), 2025, 7(1): 175-185.
|
| 19 |
皮乾坤, 卢记仓, 祝涛杰, 等. 一种基于大语言模型增强的零样本知识抽取方法[J/OL]. 计算机科学, 2025: 1-11.
|
| 20 |
|
| 21 |
张文杰. 提示词治理: DeepSeek等国产大模型内容生成的人机协同模式[J/OL]. 苏州大学学报(哲学社会科学版), 2025: 1-12.
|
| 22 |
|
| 23 |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}