


|
张何灿,研究实习员,国家信息中心大数据发展部人工智能处,研究方向为大数据与数字经济、人工智能语料体系等 |
|
郭鹏,高级咨询师,深圳数聚湾区大数据研究院(粤港澳大湾区大数据研究院)战略研究中心,研究方向为人工智能、软件工程 |
|
黄倩倩,助理研究员,国家信息中心大数据发展部人工智能处,中国人民大学信息资源管理学院,博士研究生,研究方向为人工智能、数据要素等 |
|
靳晓锟,博士研究生,中国科学院科技战略咨询研究院,研究方向为复杂网络、网络舆情等 |
收稿日期: 2024-05-20
网络出版日期: 2024-11-14
基金资助
国家自然科学基金专项项目“融合共票机制的元宇宙数字资产理论与方法研究”(62441206)
国家社会科学基金青年项目“面向多语种社会科学数据的线索发现方法研究”(22CTQ025)
国家社会科学基金青年项目“数据要素影响税收体系的机理及优化
路径研究”(24CJY048)
Copyright Data Dilemma of Building High-Quality Data System for AI: Present Situation, Coping Strategies, and Implementation Path
Received date: 2024-05-20
Online published: 2024-11-14
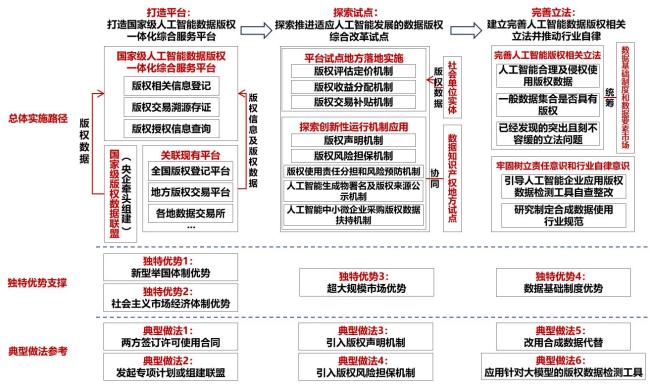
[目的/意义] 党的二十届三中全会决定明确提出,完善推动人工智能等战略性产业发展政策和治理体系。近年来,全球人工智能版权数据诉讼纷争频发,人工智能训练数据版权保护困境成为构建高质量AI数据体系面临的关键堵点和现实难题。 [方法/过程] 本研究在研究梳理人工智能数据版权保护相关学术研究和产业实践的基础上,系统性总结了应对数据版权困境的六大代表性做法,对比解析了不同做法的优缺点和适用性。 [结果/结论] 针对人工智能数据版权困境,即暂无既能促进人工智能版权数据供给又能兼顾数据版权保护工作的最优解问题,本研究在充分参考六大代表性做法解析和结合中国具备的四大独特优势基础上,研究提出系统妥善解决数据版权困境筑牢高质量AI数据体系的总体实施路径构想,分别为打造国家级人工智能数据版权一体化综合服务平台,探索推进适应人工智能发展的数据版权综合改革试点,建立完善人工智能数据版权相关立法并推动行业自律,以期对加大中国人工智能版权数据供给、制定相关政策和推动工作提供有益参考。
张何灿 , 易成岐 , 郭鹏 , 黄倩倩 , 靳晓锟 . 高质量AI数据体系面临的数据版权困境、应对策略解析与实施路径研究[J]. 农业图书情报学报, 2024 , 36(9) : 32 -43 . DOI: 10.13998/j.cnki.issn1002-1248.24-0475
[Purpose/Significance] Improving the policy and governance systems to promote the development of strategic industries such as artificial intelligence was explicitly proposed in the resolution of the Third Plenary Session of the 20th Central Committee of the Communist Party of China. In recent years, the conflict between AI companies' desire for copyrighted data and the copyright holders' protection of copyrighted data has become increasingly apparent. There have been a number of lawsuits and disputes around the world regarding copyright infringement caused by artificial intelligence. The dilemma of copyright protection of AI training data has become a difficulty and bottleneck that urgently needs to be resolved in the development of high-quality data system for AI. [Method/Process] Based on the academic research and industrial practice on the copyright protection of AI data, this study systematically summarizes six representative approaches to address the copyright dilemma of AI training data, and provides a comparative analysis of the advantages, disadvantages, and applicability of these approaches. The six representative approaches are: signing a license agreement by both parties, initiating special plans or forming alliances, introducing a copyright notice mechanism, introducing a copyright risk guarantee mechanism, replacing with synthetic data, and applying copyright detection tools to large language models. For the copyright dilemma of AI training data, there is no optimal solution that can both encourage the supply of AI copyright training data and protect the copyright of data. [Results/Conclusions] In order to provide helpful references for increasing the supply of AI copyright data, formulating relevant policies, and promoting related work, this study has proposed a concept of general implementation path to build a high-quality data system for AI to solve the copyright dilemma of AI training data, based on the comparative analysis of the above six representative approaches and combined with China's four unique advantages. These include: 1) Integrating existing platforms to build a national-level integrated service platform for copyright data for AI, with state-owned enterprises (SOEs) under the direct administration of the central government taking the lead in establishing a national copyright data alliance and connecting copyright data to the platform. 2) To collaborate with local pilots of data intellectual property rights, explore and promote comprehensive reform pilot programs of copyright data adapted to the development of AI, and continuously strengthen the cooperation efforts and willingness between AI enterprises and copyright holders. 3) The focus should be on principled or critical issues, establishing and improving legislation related to copyright data for AI and promoting industry self-regulation.
表1 部分人工智能企业与版权所有者开展商业合作情况Table1 Commercial cooperation between some AI enterprises and copyright owners |
| 达成合作时间 | AI企业 | 版权所有者/著作权人 | 版权数据类型、协议期限及金额 |
|---|---|---|---|
| 2024年7月 | 微软 | 泰勒·弗朗西斯(Taylor & Francis) | 论文期刊数据,协议期限不详、协议金额1 000万美元 |
| 2024年5月 | OpenAI | 美国新闻集团(News Corporation) | 新闻数据,协议期限5年、协议金额超2.5亿美元 |
| 2024年4月 | OpenAI | 英国金融时报 | 新闻数据,协议期限金额不详 |
| 2024年2月 | 谷歌 | Reddit平台 | 社交媒体数据,协议期限不详、协议金额6 000万美元 |
| 2024年1月 | 万兴科技 | 中广天择 | 视频数据,协议期限金额不详 |
| 2023年12月 | OpenAI | 施普林格出版集团(Axel Springer) | 新闻数据,协议期限金额不详 |
| 2023年11月 | 谷歌 | 加拿大新闻出版商 | 新闻数据,协议期限不详、协议金额1亿加元(约合7 360万美元) |
| 2023年10月 | 谷歌 | 德国Corint Media组织 | 新闻数据,协议期限不详、协议金额320万欧元(约合338万美元) |
| 2023年9月 | 华为云 | 中文在线 | 包括文字音视频等文字数据,协议期限金额不详 |
| 2023年7月 | OpenAI | 美联社 | 新闻数据,协议期限金额不详 |
表2 应对数据版权困境的六大代表性做法解析Table2 Analysis of six representative approaches to address the copyright data dilemma |
| 代表性做法 | 优点 | 不足 | 侵权风险 | 适用情形 |
|---|---|---|---|---|
| 双方签订许可使用合同 | 获取版权数据效率最高、风险最低、适用范围最广 | 版权数据采购议价成本高、批量获取个人持有版权数据效率偏低 | 无 | 资金储备较为雄厚的人工智能企业,对数据质量规模和权威性有较高要求的科研院所、咨询机构等单位 |
| 发起专项计划或组建联盟 | 继承了签订许可使用合同的部分优点,一定程度缓解版权数据采购议价成本较高的问题 | 暂未取得实质进展或成效、多方共识难达成、执行效率和灵活性不足等 | 低 | 业内具有一定影响力、话语权较大或版权数据资源独特等企业发起或参与 |
| 引入版权声明机制 | 无获取版权授权的溯源和采购成本、适用范围广 | 声明易被忽视、操作技术性要求较高、大量作品“退出”将影响大模型性能等 | 中 | 有一定合规版权数据储备和技术能力的人工智能企业 |
| 引入版权风险担保机制 | 提升企业口碑、增加社会信任,在一定程度减少人工智能用户和版权所有者之间的诉讼纷争 | 部分用户使用过程中触发的侵权责任转移至企业自身,保障条款往往对担保情形有一定额外要求 | 中 | 有一定合规版权数据储备或是法律资金资源充足的人工智能企业 |
| 改用合成数据代替 | 生产数据效率高、成本低、可持续 | 无法完全根除版权保护风险隐患,进一步加大侵犯版权察觉溯源取证的难度 | 低 | 一些特定如数据原创性要求相对较低、版权数据规模要求相对较小等的场景应用 |
| 应用针对大模型的版权检测工具 | 缓解版权所有者察觉侵权和侵权取证维权问题,提升版权作品的创作动力和创作环境,帮助人工智能企业提前发现未获授权的版权数据 | 当前适用于人工智能大模型的监测工具较少问世且技术尚不成熟、提高企业版权数据管理成本 | 不涉及 | 具有公信力的第三方机构 |
| 1 |
于凤霞. 抓住人工智能“牛鼻子”加快形成新质生产力[EB/OL]. (2024-01-10)[2024-05-11].
|
| 2 |
张文娟, 邓辉, 艾政阳, 等. 我国AI大模型数据集建设发展刍议[J]. 人工智能, 2024, 11(3): 85-95.
|
| 3 |
腾讯研究院. AIGC发展趋势报告2023: 迎接人工智能的下一个时代[R/OL]. 北京: 腾讯研究院, 2023.
|
| 4 |
盘和林, 茹少峰, 易成岐. 深入推进数字经济创新发展[N]. 经济日报, 2024-06-12(010).
|
| 5 |
蔡津津. AIGC时代新闻舆论工作新阵地——面向大模型的可信训练数据集与服务能力建设[J]. 中国传媒科技, 2023(10): 79-83.
|
| 6 |
新华社. 中共中央 国务院关于构建数据基础制度更好发挥数据要素作用的意见[EB/OL]. (2022-12-19)[2024-05-11].
|
| 7 |
高雅文, 来小鹏. 生成式人工智能语料版权问题研究[J]. 出版广角, 2024(5): 27-34.
|
| 8 |
张涛. 生成式人工智能训练数据集的法律风险与包容审慎规制[J]. 比较法研究, 2024(4): 86-103.
|
| 9 |
张平. 人工智能生成内容著作权合法性的制度难题及其解决路径[J]. 法律科学(西北政法大学学报), 2024, 42(3): 18-31.
|
| 10 |
周文康, 费艳颖. 生成式人工智能创作使用作品的合理使用调适[J]. 科技与法律(中英文), 2024(3): 77-87.
|
| 11 |
张惠彬, 肖启贤. 人工智能时代文本与数据挖掘的版权豁免规则建构[J]. 科技与法律(中英文), 2021(6): 74-84.
|
| 12 |
郑飞, 夏晨斌. 生成式人工智能的著作权困境与制度应对——以ChatGPT和文心一言为例[J]. 科技与法律(中英文), 2023(5): 86-96.
|
| 13 |
林秀芹. 人工智能时代著作权合理使用制度的重塑[J]. 法学研究, 2021, 43(6): 170-185.
|
| 14 |
林华. 大数据的法律保护[J]. 电子知识产权, 2014(8): 80-85.
|
| 15 |
高阳. 衍生数据作为新型知识产权客体的学理证成[J]. 社会科学, 2022(2): 106-115.
|
| 16 |
冯晓青. 数据财产化及其法律规制的理论阐释与构建[J]. 政法论丛, 2021(4): 81-97.
|
| 17 |
梅夏英. 企业数据权益原论: 从财产到控制[J]. 中外法学, 2021, 33(5): 1188-1207.
|
| 18 |
崔国斌. 大数据有限排他权的基础理论[J]. 法学研究, 2019, 41(5): 3-24.
|
| 19 |
冯晓青. 知识产权视野下商业数据保护研究[J]. 比较法研究, 2022(5): 31-45.
|
| 20 |
朱长宝. 论在线浏览、欣赏目的临时复制的法律保护[J]. 电子知识产权, 2016(10): 79-87.
|
| 21 |
张金平. 人工智能作品合理使用困境及其解决[J]. 环球法律评论, 2019, 41(3): 120-132.
|
| 22 |
|
| 23 |
叶兆驰. 人工智能生成物的侵权及解决路径[J]. 中南民族大学学报(人文社会科学版), 2024, 44(5): 156-163, 223.
|
| 24 |
潘香军. 论机器学习训练集的著作权风险化解机制[C]//《上海法学研究》集刊2023年第6卷——2023年世界人工智能大会青年论坛论文集. 香港: 2023年世界人工智能大会青年论坛论, 2023: 12.
|
| 25 |
邵红红. 生成式人工智能版权侵权治理研究[J]. 出版发行研究, 2023(6): 29-38.
|
| 26 |
|
| 27 |
刘小璇, 张虎. 论人工智能的侵权责任[J]. 南京社会科学, 2018(9): 105-110, 149.
|
| 28 |
|
| 29 |
朱阁. “AI文生图”的法律属性与权利归属研究[J]. 知识产权, 2024, 34(1): 24-35.
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}